프로그램의 실행 과정은 두 가지 상황이 번갈아 진행되는데, 그것은 한동안 CPU 연산이 계속되는 ( CPU burst ) 상황과, I/O 작업이 이루어지는 ( I/O burst ) 상황이다. CPU 연산이 주를 이룰 때 ( CPU 집중 ) 프로세스라고 부르고 I/O 작업이 주를 이룰 때 ( I/O 집중 ) 프로세스라고 한다. CPU 스케줄링은 CPU의 ( idle ) 시간을 줄이기 위해 도입되었다.
2. CPU 스케줄링 알고리즘을 평가하는 기준과 거리가 먼 것은?
② 동시성(cocurrency)
3. CPU 스케줄링의 평가 기준 사이의 관계를 잘못 설명한 것은?
③ 시스템 정책 우선으로 스케줄링하면 CPU 활용률은 높아진다
4. CPU 스케줄링이 행해지는 상황들을 나열하였다. 비어 있는 상황을 적어라.
첫째, 스레드에게 할당된 CPU 타임 슬라이스가 소진되었을 때
둘째, 스레드가 자발적으로 CPU를 반환하는 경우
셋째, 현재 실행중인 스레드보다 더 높은 순위의 스레드로부터 내려진 입출력이 완료되어 I/O 인터럽트가 발생한 경우
넷째, 스레드가 I/O를 요청하는 시스템호출을 실행하여 블록 상태가 되거나, 자원을 기다리는 상태가 될때, 다른 스레드에게 CPU를 할당하는 경우
5. 타임 슬라이스에 대한 설명으로 틀린 것은?
④ 타임 슬라이스가 클수록 컨텍스트 스위칭의 횟수가 증가한다
6. 선점과 비선점 중 선택하여 빈 칸을 채워라
스레드가 CPU를 할당받아 일단 실행을 시작하면 완료되거나 CPU를 더 이상 사용할 수 없는 상황이 될 때까지 스레드를 강제로 중단시키지 않는 방식을 ( 비선점 ) 스케줄링이라고 하며, 커널이 현재 실행 중인 스레드를 강제로 중단시켜 준비 리스트로 이동시키고, 스케줄링을 통해 다른 스레드에게 CPU를 넘겨주는 방식을 ( 선점 ) 스케줄링 이라고 한다. ( 비선점 ) 스케줄링의 경우, 스레드가 더 이상 CPU를 사용할 수 없는 상황에야 비로소 스케줄링이 이루어 진다. PC와 같은 범용 시스템에서 ( 비선점 ) 스케줄링은 현재는 거의 사용되고 있지 않다.
7. 다음 스케줄링이 선점 스케줄링인지 비선점 스케줄링인지 표기하라.
(1) 선입 선처리 (FCFS) - 비선점
(2) 최단 작업 우선 스케줄링 (SJF) - 비선점
(3) 최소 잔여 시간 우선 스케줄링 (SRTF) - 선점
(4) 라운드 로빈 스케줄링 (RR) - 선점
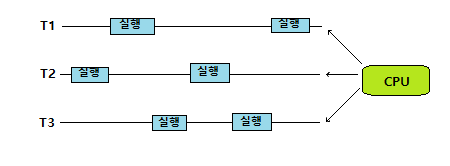
8. 다음 그림은 3개의 프로세스 p1, p2, p3이 실행되는 과정을 보여준다. 선점 스케줄링과 비선점 스케줄링 중 어떤 것이 사용되었는지 판단하고 그 이유를 설명하라.
비선점 스케줄링이다. T1이 시작하면 종료하기 전 까지 스케줄링이 이루어지지 않으며, T1이 종료될때 스케줄링이 이루어져 T2가 실행된다. T2의 실행 중 I/O가 발생하면 T2를 중단시키고 스케줄링을 실행하여 T3를 선택한다. T3이 실행 중 yield()를 호출하면 준비상태인 T2를 스케줄링하고 실행시킨다. T2가 끝날때 다시 스케줄링이 이루어져 T3이 실행된다
9. 다음은 무엇에 대한 설명인가?
스케줄링 과정에서 선택되지 못한 채 오랫동안 준비 리스트에 있는 상황
④ 기아
10. 다음은 무엇에 대한 설명인가?
스레드가 준비 리스트에 머무르는 시간에 비례하여 우선수위를 높여주는 기법
③ 에이징(aging)
11. 다음은 무엇에 대한 설명인가?
프로세스나 스레드가 특정 CPU에서 실행되도록 제한하는스케줄러의 특징
① CPU 친화성 ( CPU affinity )
12. 에이징(aging) 기법은 CPU 스케줄링의 어떤 단점을 극복하기 위한 정책인가?
기아발생
13. RR(Round Robin) 스케줄링을 사용할 때 오늘날 합리적인 타임 슬라이스로 적합한 것은?
③ 50 밀리초(20~120밀리초가 적당)
14. 스레드가 종료할 때 비로소 새 스레드를 스케줄한다면 이 운영체제는 선점 스케줄링을 하는가 아니면 비선점 스케줄링을 하는가?
비선점 스케줄링
15. 다음은 에이징을 설명하는 문장이다. 빈 칸에 적절한 단어는 무엇인가?
스레드가 준비 리스트에 머무르는 시간에 비례하여 스레드의 ( )을/를 높이는 기법이다.
① 우선순위
16. 다음 CPU 스케줄링 알고리즘 중에서 실현성이 없는 것은?
② SJF (실행시간 예측 불가능)
17. 다음 중 모든 스레드에게 CPU를 가장 공평하게 나누어 주는 스케줄링 기법은?
① RR
18. 다음 중 기아 발생 가능성이 가장 큰 CPU 스케줄링은?
④ SJF
19. 다음 중 기아가 전혀 발생하지 않는 CPU 스케줄링은?
① RR
20. 어떤 연구소에서 컴퓨터 시스템 사용자들을 책임연구원, 연구원, 연구 보조원의 3 그룹으로 나누어 놓고 각 사용자들이 생성된 프로세스나 스레드의 우선순위를 다르게 매기려고 한다. 가장 적절한 CPU 스케줄링은 무엇인가?
④ MLQ
21. RR(Round Robin) 스케줄링에서 스레드에게 할당하는 타임 슬라이스의 크기에 관한 설명 중 틀린 것은?
② 타임 슬레이스가 클수록 더 균등한 알고리즘이 된다
22. MLFQ(Multi-Level Feedback Queue) 스케줄링에 대한 설명으로 옳은 것은?
② 스레드의 기아를 막기 위해 큐에 대기하는 시간이 오래되면 위 레벨의 큐로 이동시킨다
23. 단일 코어 CPU와 달리 멀티 코어 CPU에서 스케줄링할 때 특별히 고려할 사항과 거리가 가장 먼 것은?
① 타임 슬라이스
24. 코어 친화성 혹은 CPU 친화성과 관계가 깊은 것은?
① 캐시
25. 멀티 코어 CPU를 가진 시스템에서 CPU 스케줄링 알고리즘은 스레드를 어떤 코어에서 실행시킬 것인지에 따라 컨텍스트 스위칭 후 오버헤드가 달라진다고 한자.
(1) 구체적으로 어떤 오버헤드가 문제인가? 일반적으로 코어는 내부의 CPU 캐시를 가지고 있다. 캐시에는 현재 실행중이거나 이전에 실행되었던 스레드 코드와 데이터가 적재되어 있다. 만일 스레드가 한 코어에서 실행되다가 중단된 후 동일한 코어에서 다시 실행된다면 코어 내부의 캐시에 스레드 코드와 데이터가 그대로 남아있을 가능성이 높기 때문에 메모리로부터 스레드 코드와 데이터를 적재할 가능성이 상대적으로 낮다. 하지만, 만일 스케줄된 스레드가 다른 코어에서 실행되도록 스케줄 되었다면 메모리로부터 스레드 코드와 데이터가 스케줄된 코어 내부의 캐시로 적재되어야 한다. 스레드를 어떤 코어에 할당하느냐에 따라 컨텍스트 스위칭의 오버헤드가 달라진다.
(2) 이 오버헤드를 줄일 수 있는 해결책은 무엇인가? 스레드가 특정 코어에서만 실행되도록 스케줄링을 제한하도록 하면 된다. 이것은 CPU 친화성 혹은 코어 친화성이라고 한다.
26. 멀티 코어 CPU를 가진 시스템에서 스케줄링이 잘못되면 한 코어에만 스레드가 몰리고 다른 코어는 놀게 되는 현상이 나타난다. 이러한 현상을 무엇이라고 부르고 그 해결책은 무엇인가?
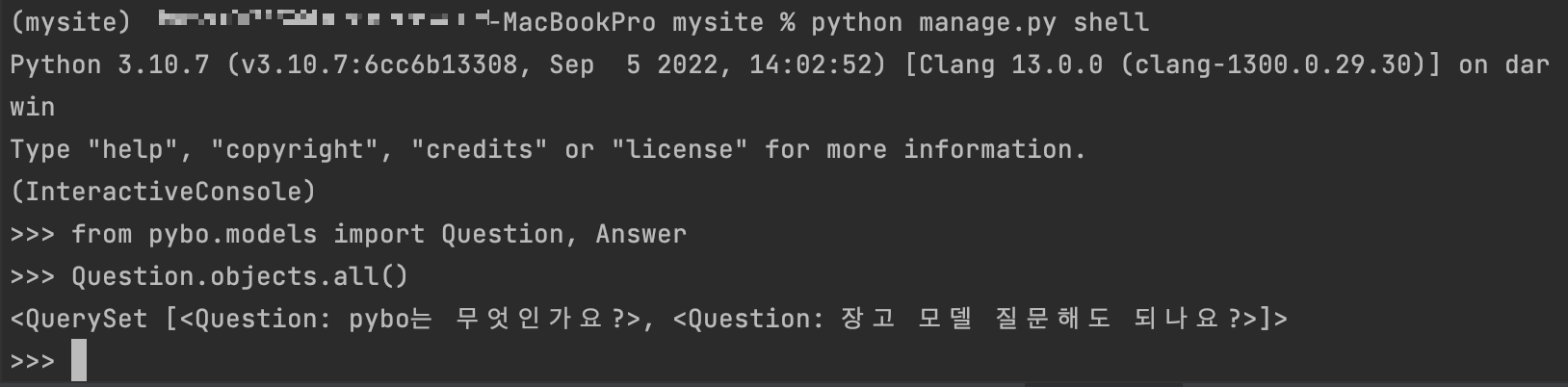
전에 모델을 만들어 보았으니 이제 사용법을 장고 셸로 배워보자. 일단 python manage.py shell 명령어로 장고 셸을 열자.
명령어를 입력하면 셸이 열린다. 반드시 장고 셸로 실행해야하는 이유는 장고 셸에는 장고에 필요한 환경들이 자동으로 설정되어 실행되기 때문이다.
장고 셸에 Question, Answer 모델을 import 해서 사용한다. 장교 셸에 from pybo.models import Question, Answer 명령어를 수행하자. 그 후 일단 Question 모델을 이용해 질문 데이터를 만들어보자.
question,answer 모델을 import 한후, create_date 에 적어넣을 timezone 도 import 한다. 객체 Question모델의 객체q 를 생성한후 속성들을 채워넣는다.create_date 의 속성은 DateTimeField 타입이므로 timezone.now()로 현재시간을 대입하였다. q.save()로 저장을 하면 데이터 하나가 생성된다. q.id로 확인을해보면 id 값이 생긴걸 확인할 수 있다. id 는 모델 데이터의 유일한 값으로 프라이머리 키 (PK) 라고도 한다. 이 값은 데이터를 생성할 때마다 1씩 증가된다.
질문을 하나 더 만들어보자.
실수를 한 부분이 있다
사진을 보면 q.save 를 했는데 경고문이 뜨면서 저장이 앉되서 해맨 흔적이 있다. q.save 가 아니라 q.save() 를 해야한다. 나처럼 실수하는 사람이 없기를 바라는 마음으로 올려보았다. 질문을 하나 더 작성하니 q.id 가 2가 된것을 확인할 수 있다.
이제 만든 데이터들을 조회해 보자. Question.objects.all() 명령어를 쳐보자.
이번이도 오타가나서 경고문이 나타났었다
오타가 발생해서 실행이 제대로 되지않게 명령어를 제대로 입력해야한다. Question모델의 데이터는 Question.objects를 통해서 조회할수 있고 뒤에붙은 .all()은 모든 데이터를 조회하는 함수이다. 명령을 수행하면 QuerySet의 객체가 리턴된다. 이것들은 Question 객체를 포함한다. 객체 안에 1 과 2 는 데이터의 id 값이다. 뒤에 id 값이 아닌 제목을 표시하고싶다면 Question 모델에 __str__ 메서드를. 추가하면 id 값 대신 제목을 표시할 수 있다.
pybo/models.py 에
def __str__(self): return self.subject
를 추가하면 된다. Question 모델을 변경하려는 것이였으므로 Question 모델 안에다가 작성해야만한다. 그리고 모델이 변경되었으므로 장고 셸을 재시작해야 변경된 결과를 확인할 수 있다.
장고 셸을 재시작후 다시 모델들을 import 한후 Question.obbjects.all() 을 하면 이전과 달리 제목이 표시 된다. 모델의 메서드가 추가된 경우에는 makemigrations, migrate 를 수행할 필요가 없다. makemigrations, migrate 는 모델의 속성이 변경되었을 경우에 사용하는것이다.
filter 함수를 사용해 id 값이 1 인 데이터를 조회해보면
id 값은 유일한 값이기 때문에 get 함수를 이용해도 비슷한 결과를 얻을수 있다. 하지만 filter 함수는 filter함수에 맞는 여러개가 리턴되기때문에 QuerySet 이 리턴된다. get 함수는 Question 모델 객체가 리턴된다. get 함수는 조건에 맞는 데이터가 1개일 경우일때 사용한다. 데이터가 여러개일때 get 함수를 사용하면 오류가 난다. 보통 get 함수는 id 와 같은 유일한 값으로 조회할 경우에만 사용한다.
filter 함수를 사용해 subject에 'pybo' 라는 문자열이 포함된 데이터만 조회할수도 있다.
filter 함수는 이것 말고도 다양하다.
filter 함수 사용법은 장고 공식 문서를 참조해서 더 알아보자. 장고 공식 문서는 장고 개발시 필수로 참조해야하는 문서이다.
id 값이 1인 데이터를 q 에 초기화후 subject 속성을 수정후 저장한후 q내용을 확인해 보면 변경된 것을 알수있다.
이번엔 id값이 1 인 Question 데이터를 삭제해보자. 먼저 id값이 1 인 데이터를 조회하자.
q 에 id 값이 1인 데이터를 초기화후 q.delete() 하면 (1, {'pybo.Question': 1}) 이 출력된다. 이는 Question 모델이 1개 삭제 되었다는것을 의미한다. 그후 질문 모델 전체를 조회해보면 질문이 삭제되고 하나만 남은것을 알 수 있다.
이제 답변을 해보자. Question 데이터를 작성하고 조회하고 수정하고 삭제한것과 비슷하다. 먼저 id 값이 1 인 질문 데이터는 삭제했으므로 id 값이 2인 데이터를 조회해서 데이터를 작성해보자.
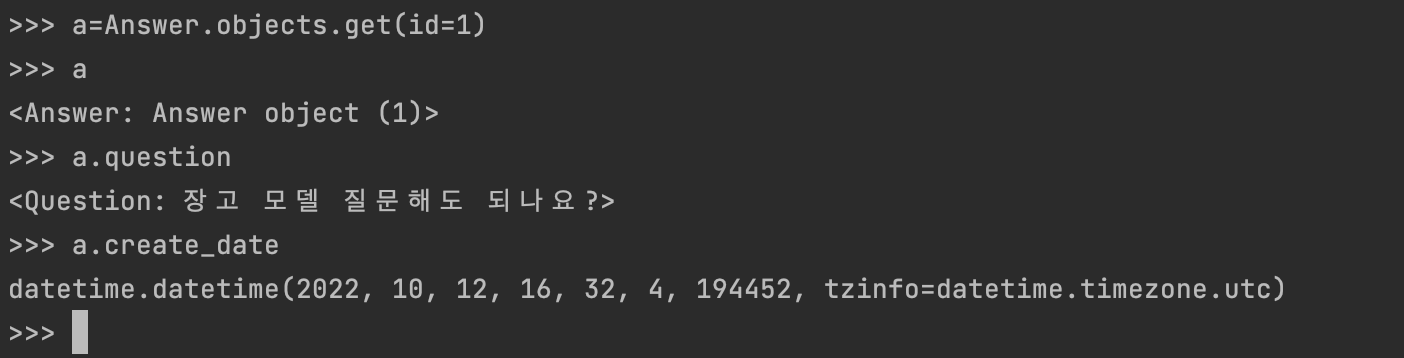
q에 id값이 2인 Question 데이터를 넣고, a에 Answer 데이터를 작성한후 저장하자. a.id 를 보면 id 가 1이 된것을 볼수있다.
Question 때와 같이 id 값을 이용해 데이터를 찾을 수 있다.
Answer 모델의 속성을 이용해 다양한 정보를 조회할 수 있다.
질문을 이용하여 답변을 찾는것도 가능하다.
q.answer_set.all() 명령을 하면 질문에 연결된 답변 모두를 가져올 수 있다. Question 모델에는 answer_set이라는 속성은 없지만 Answer 모델에는 Question 모델이 ForeignKey로 연결되어 있기 때문에 q.answer_set 과 같은 접근이 가능하다. 하지만 반대로는 불가능하다. 상식적으로 질문하나에는 여러개의 답변이 가능하므로 q.answer_set 이 가능하지만 답변하나에는 여러개 질문이 있을수 없으므로 a.question_set 은 불가능하다. 답변하나에는 질문 하나만 가능하기 때문에 a.question 만 가능하다.
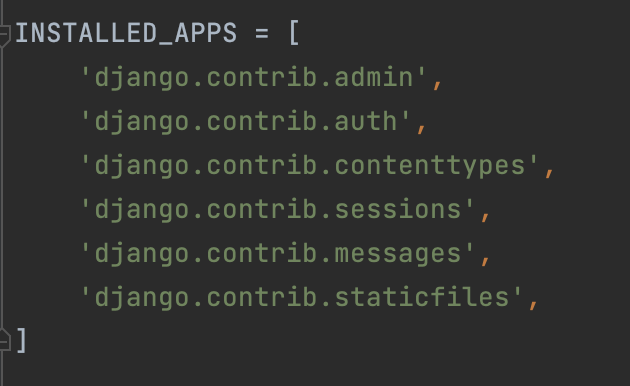
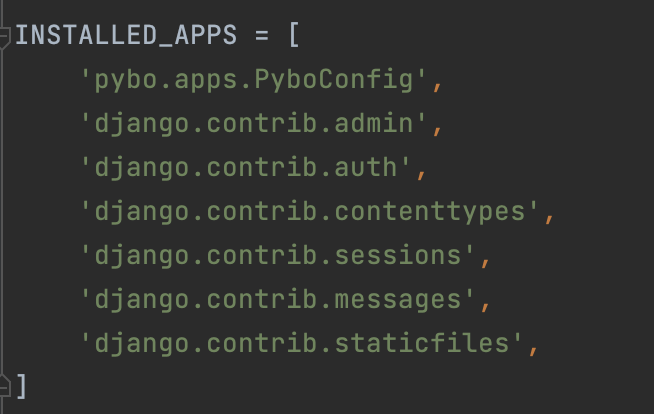
18개의 적용되지않은 mirgrations 들이 있다. admin, auth, contenttypes, sessions 앱에 migration을 적용하기전까지 프로젝트가 정상적으로 작동하지 않을것이라고 한다. python manage.py migrate 명령어로 적용하라고 한다. admin, auth, contenttypes, sessions 앱들은 장고 프로젝트 생성시 기본설치되는 앱이다. 설치된 앱은 config/settings.py 에 적혀있다.
config/settings.py 를 잘 살펴보자
경고문에 적힌 앱들말고도 messages, staticfiles 앱들도 있는데 이 두개의 앱은 데이터베이스와 관련이 없어서 경고문에 나오지 않은것이라고 한다.
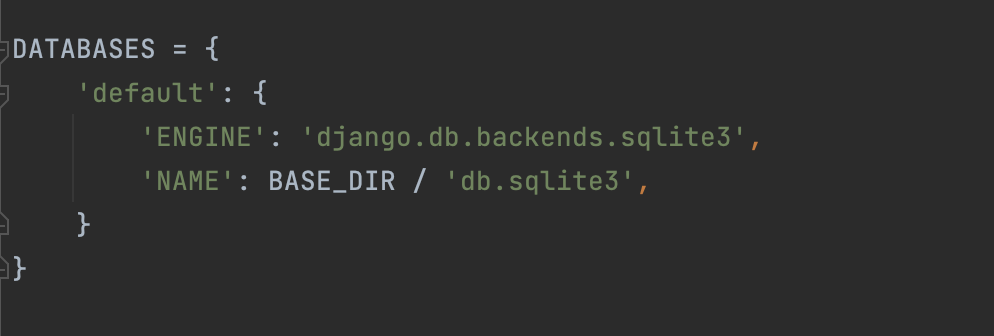
config/settings.py 파일을 잘 살펴보면 데이터베이스에 관한 정보도 같이 들어있다.
데이터베이스의 엔진은 django.cbb.backends.sqlite3 이고 데이터베이스 파일의 위치는 BASE_DIR 디렉토리 밑에 db.sqlite3 파일에 저장되어있다. BASE_DIR은 프로젝트 디렉토리로 나는 /Users/<사용자명>/projects/mysite 이다.
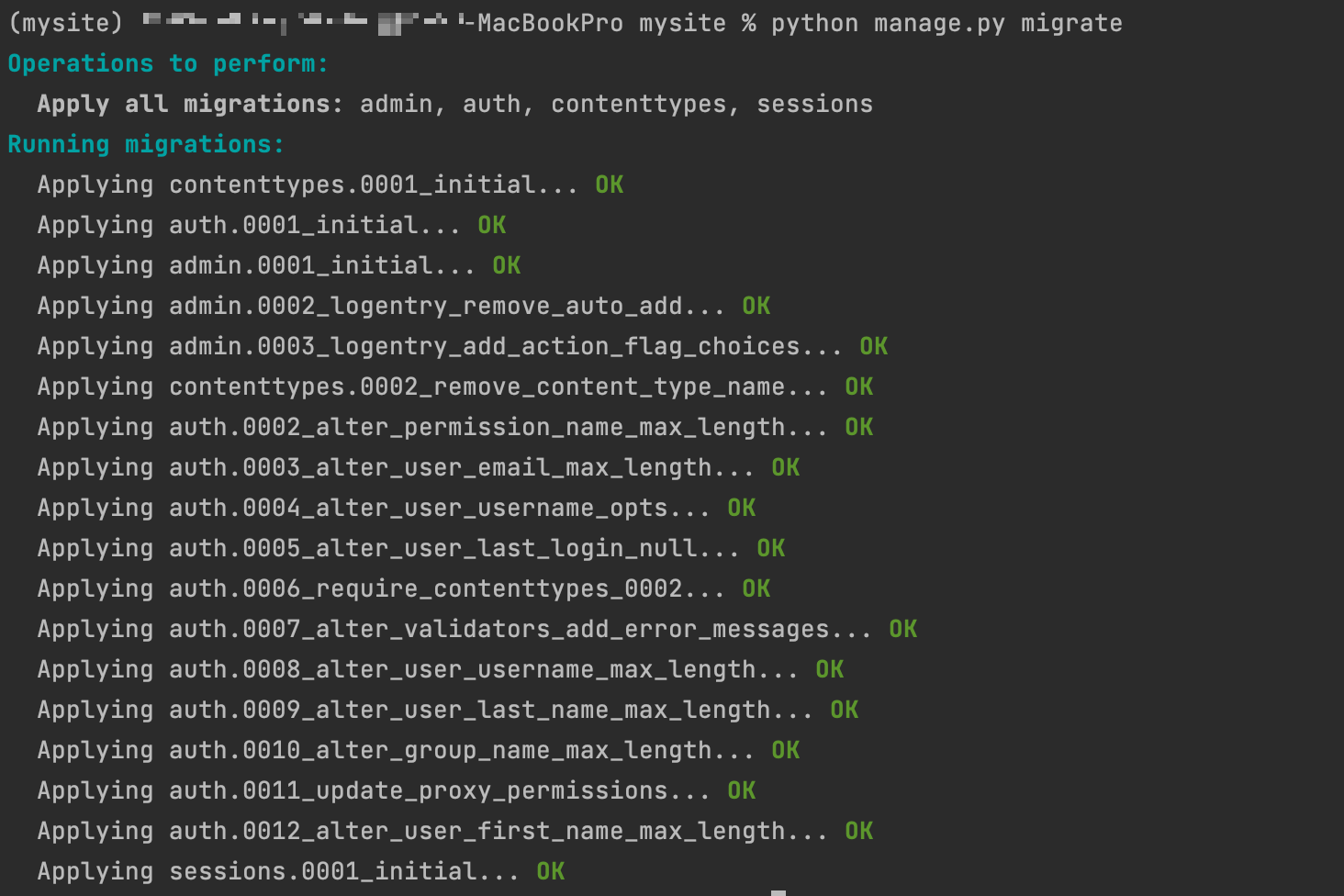
이제 경고문이 하라는대로 python manage.py migrate 명령을 실행해 해당하는 앱들이 필요로 하는 데이터베이스 테이블들을 생성하자.
자동으로 진행이 된다
명령어를 실행하면 각 앱들이 사용하는 테이블들이 자동으로 생성된다.
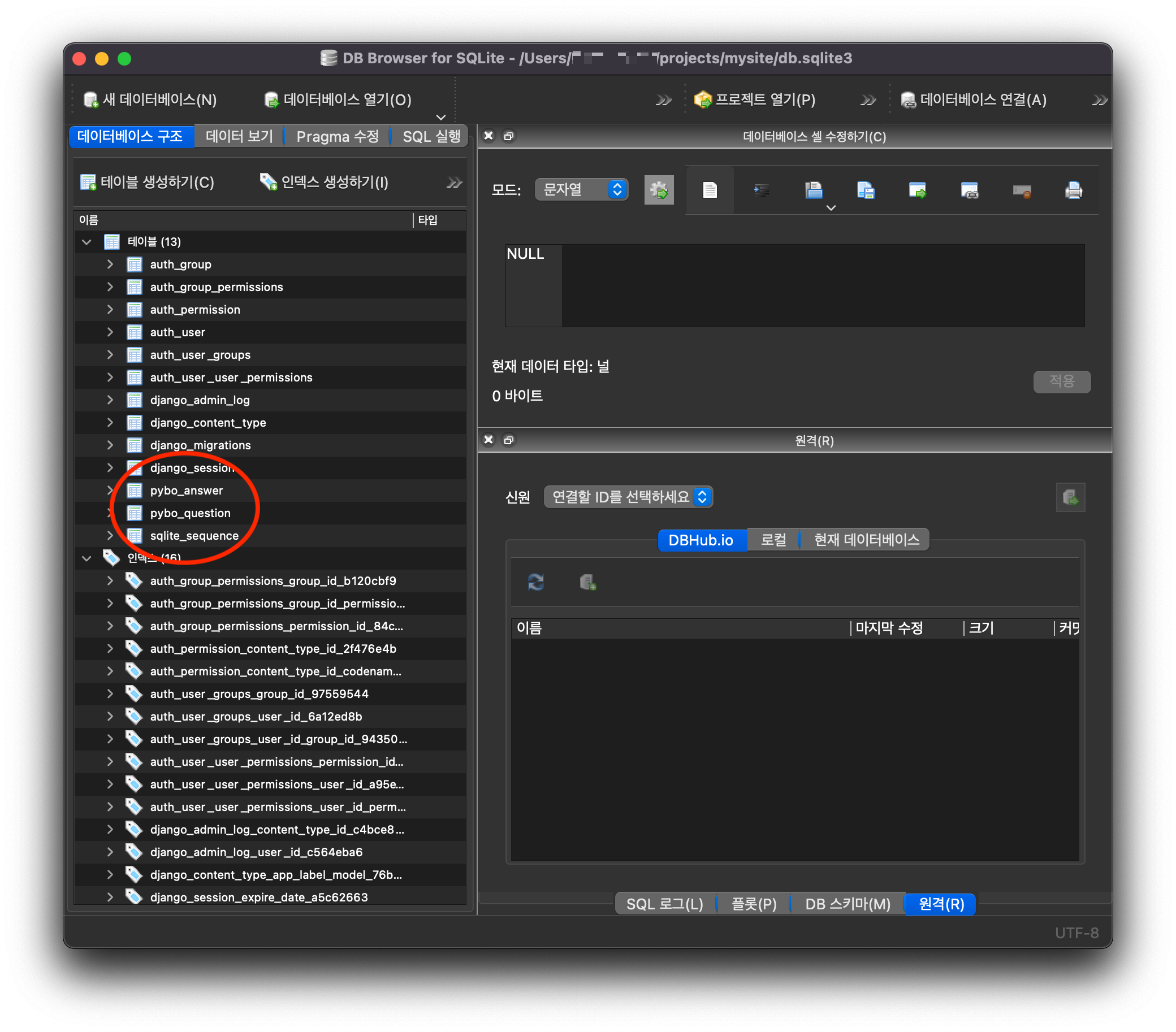
[ DB Browser for SQLite ]
생성된 테이블들은 SQLite 의 GUI 도구인 "DB Browser for SQLite"를 설치하면 볼수 있다.
[ 데이터베이스 열기 -> /Users/<사용자명>/projects/mysite/db.sqlite3 ] 파일을 선택하자.
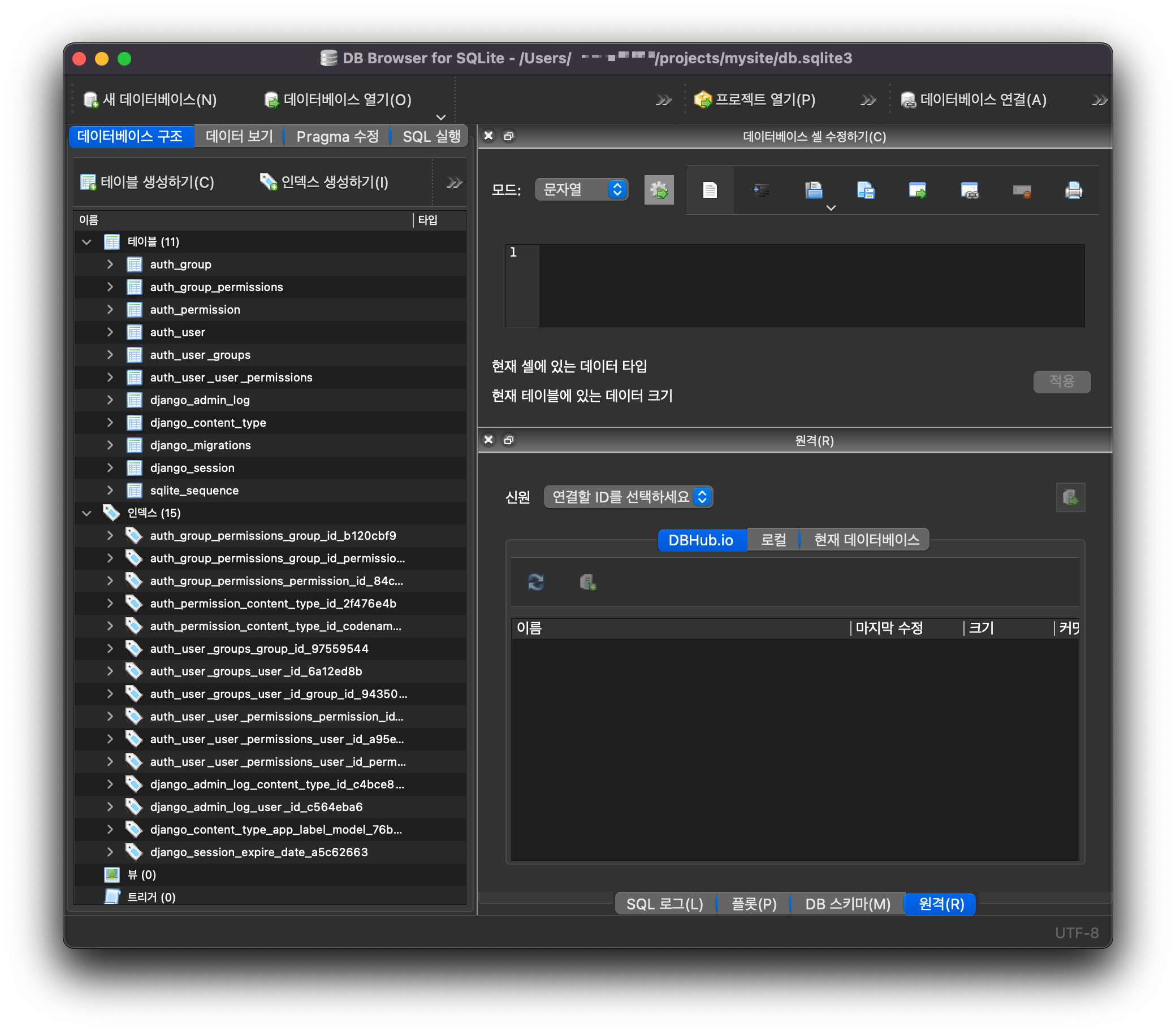
이런 화면이 나온다
정확히 무슨 내용인지 자세히 볼 필요는 없다. 장고의 장점 중 하나는 테이블 작업을 위해 직접 쿼리문을 수행하지 않아도 된다는 점이다. 장고의 ORM을 사용하면 쿼리문을 몰라도 데이터 작업을 쉽게 할 수 있다. 여기서 쿼리문이란 데이터베이스의 데이터를 생성, 조회, 수정, 삭제하기위해 사용하는 문법이다.
[ 모델 작성법 ]
우리가 만드는 pybo 라는 게시판은 질문과 답변을 할 수 있는 파이썬 게시판 서비스이다. 그러므로 질문과 답변에 해당하는 데이터 모델이 있어야만 한다.
질문과 답변 모델에는 어떤 속성들이 필요할까? 만드는 사람에 따라 다르겠지만 일반적으로 질문의 제목,질문의 내용, 질문한 날짜 가 필요하고 답변에는 받은 질문,답변의 내용,답변한 날짜가 필요하다.
정리해보자면
Question 모델에 들어갈 속성들은 : subject,content,create_date 가 들어가고
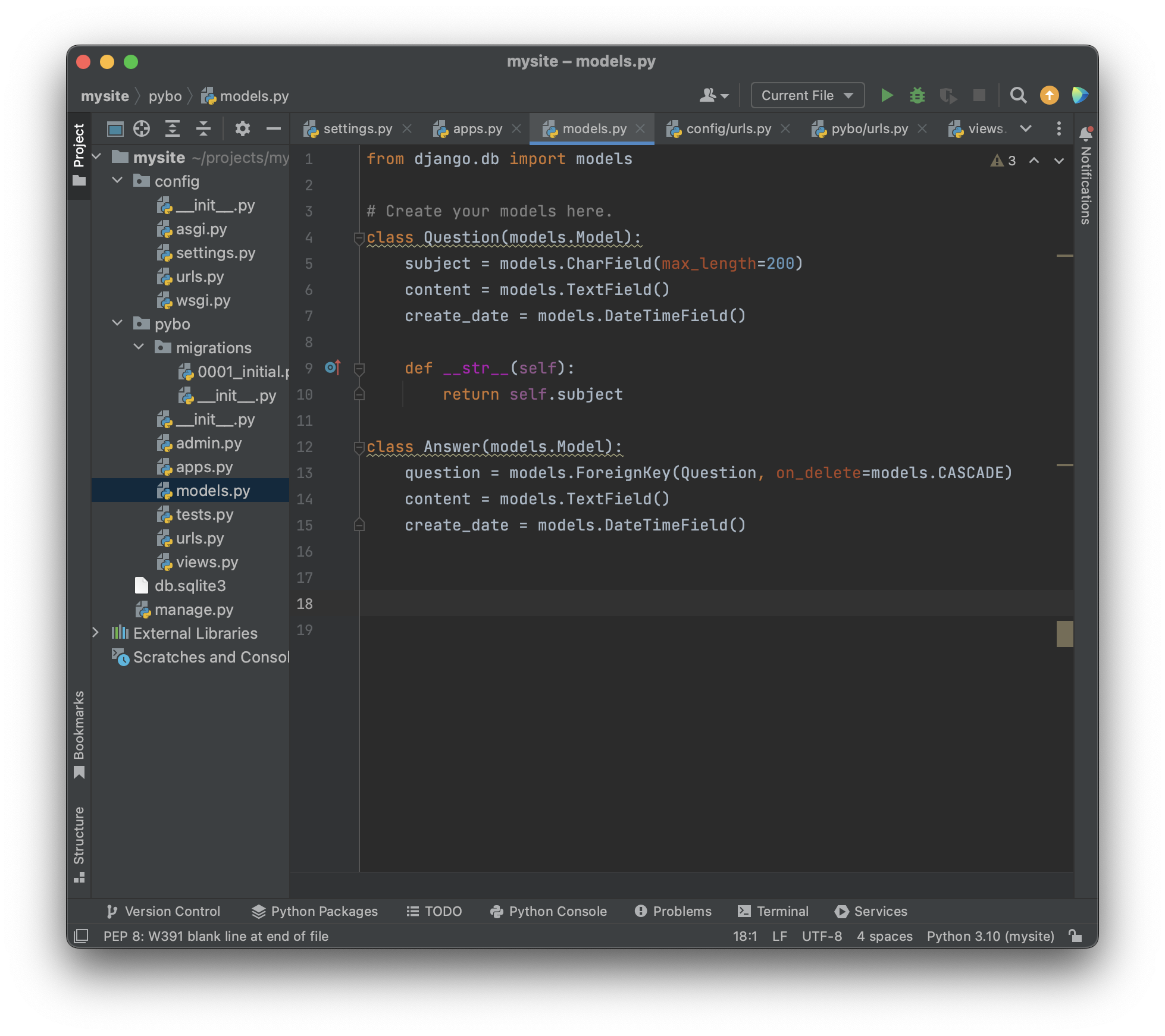
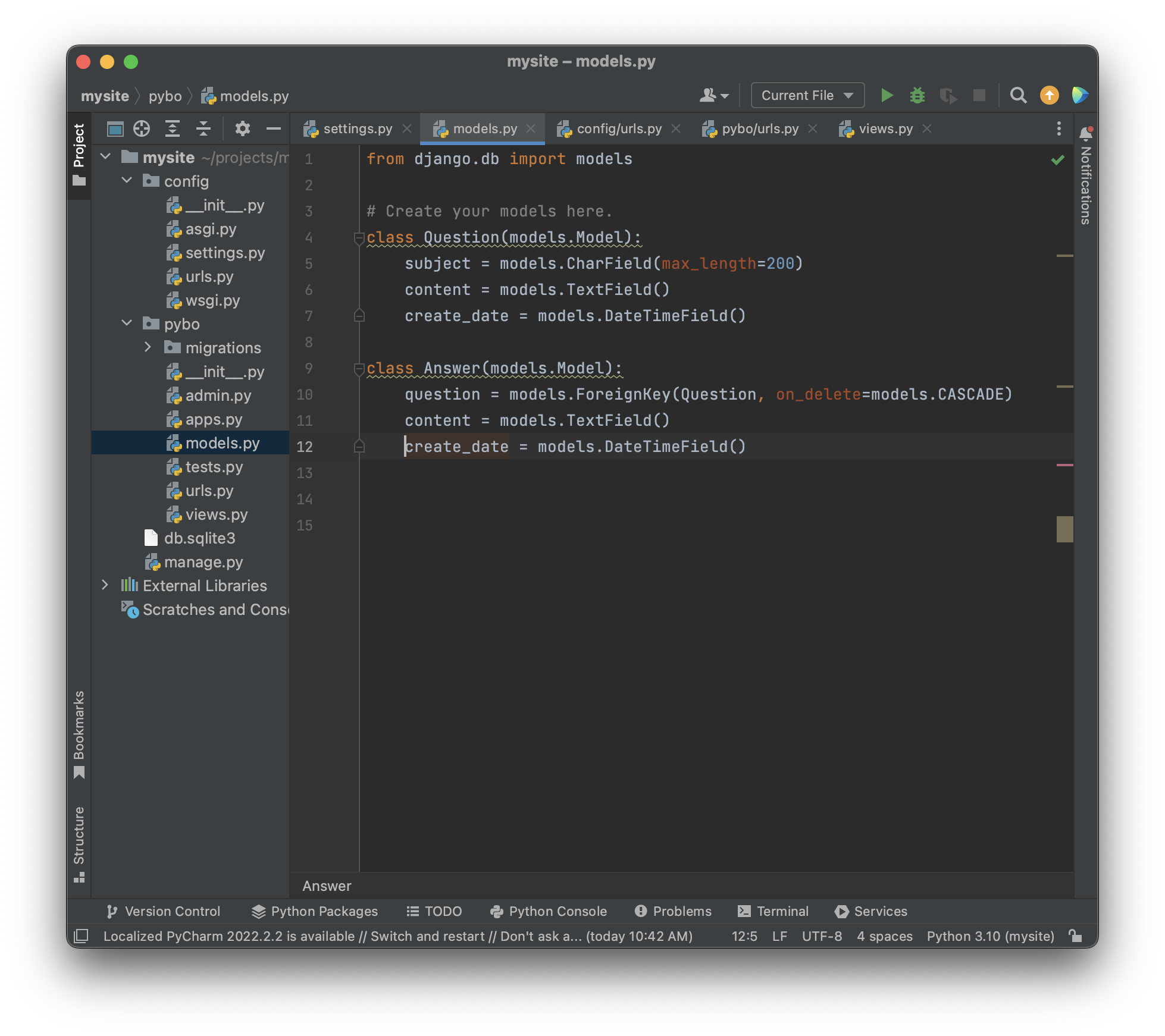
Answer 모델에 들어갈 속성들은 : question, content,create_date 속성들이 들어갈 것이다. 이것을바탕으로 pybo/models.py 에 작성해보면
보면 대충 이해할 수 있는데, Question 모델에 subject(제목)속성, content(내용)속성, create_date(작성날짜)속성이 들어있고, subject에는 최대 200글자까지 가능한 CharField()를 사용했고, content에는 글자수 제한이 없는 TextField()를 사용했고, create_date 속성에는 날짜와시간에 관계된 속성인 DateTimeField 를 사용했다.
Answer 모델에는 질문에 답변을 해야하므로 Question 모델을 속성으로 가진다. 기존의 모델을 속성으로 연결을 하려면 ForeignKey 를 사용해야한다. on_delete=models.CACADE 는 Answer 모델과 연결된 Question, 질문이 삭제 될 경우 답변도 같이 삭제된다는 의미이다.
[ 테이블 생성 ]
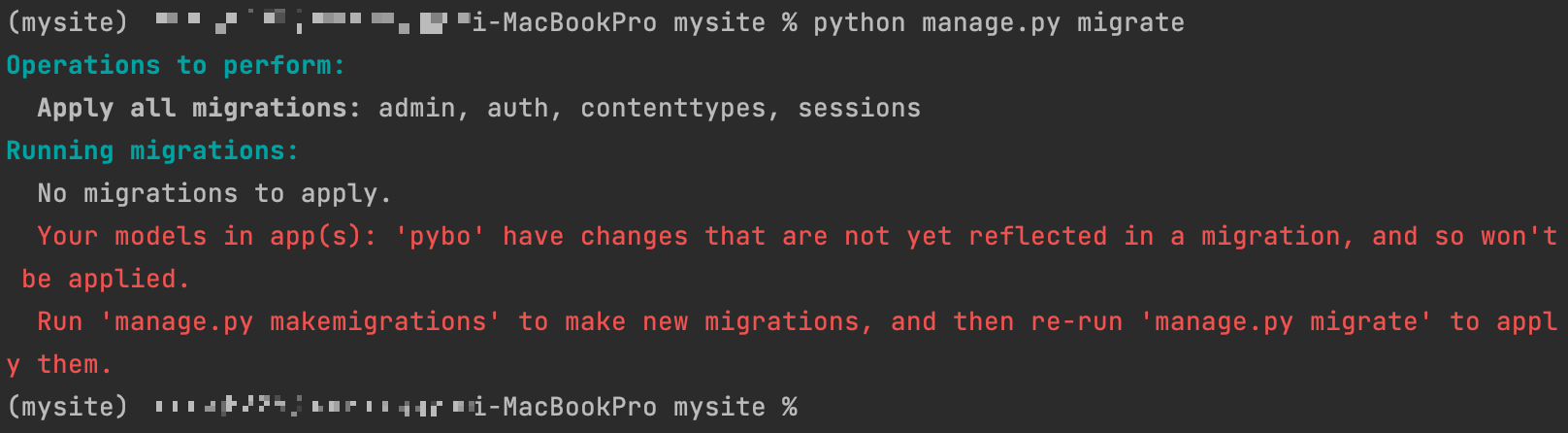
이제 이 모델들을 이용해 테이블을 생성해야한다. 일단 config/setting.py 에있는 저번에 봤던 INSTALLED_APPS 에 항목을 추가해야한다.
맨 윗줄에 추가했다
추가한 pybo.apps.PyboConfig 클래스는 pybo/apps.py 파일에 있는 클래스이다. pybo 앱 생성시 자동으로 만들어지는 파일이라 따로 만들 필요는없다.
이제 테이블 생성을 위해 python manage.py migrate 명령어를 쳐보면,
또 경고문이 나온다
경고문의 의미는 pybo 가 아직 migration 에 반영되지 않는 변경 사항이 있으므로 적용되지 않는다. 'manage.py makemigrations' 명령어를 수행해서 새 migrations 를 만들고, 'manage.py migrate' 명령을 다시 수행해서 적용시켜라. 라는 뜻이다. 그럼 하라는대로 python manage.py makemigrations 명령을 수행하면,
model Question 과 Answer과 생성되었다
makemigrations 명령어는 모델을 생성하거나 변화가 있었을 경우에 실행해야 하는 명령이다. 위 명령을 실행하면 pybo/migrations/0001_initail.py 파일이 자동으로 생성된다.
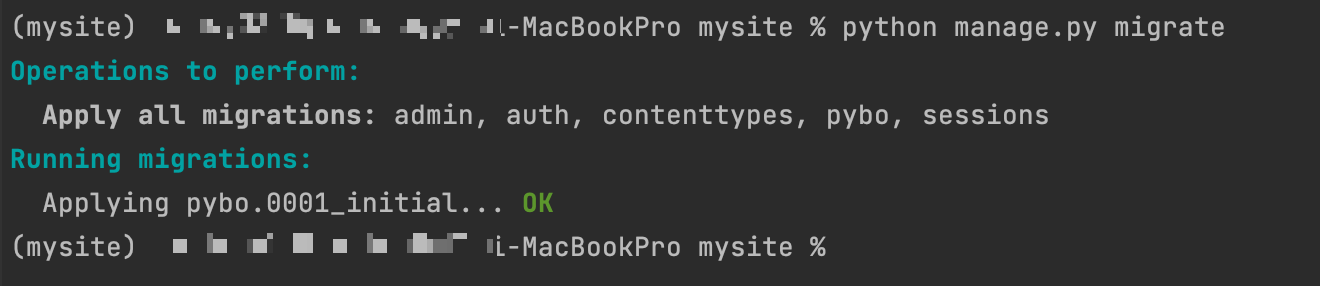
이제 다시 python manage.py migrate 명령어를 수행하면
이제야 문제없이 된다
경고문이 안뜨고 명령어가 잘 실행된다. migrate 명령으로 실제 테이블을 생성한것이다. 오류없이 잘 실행된것을 확인하려 전에 깔았던
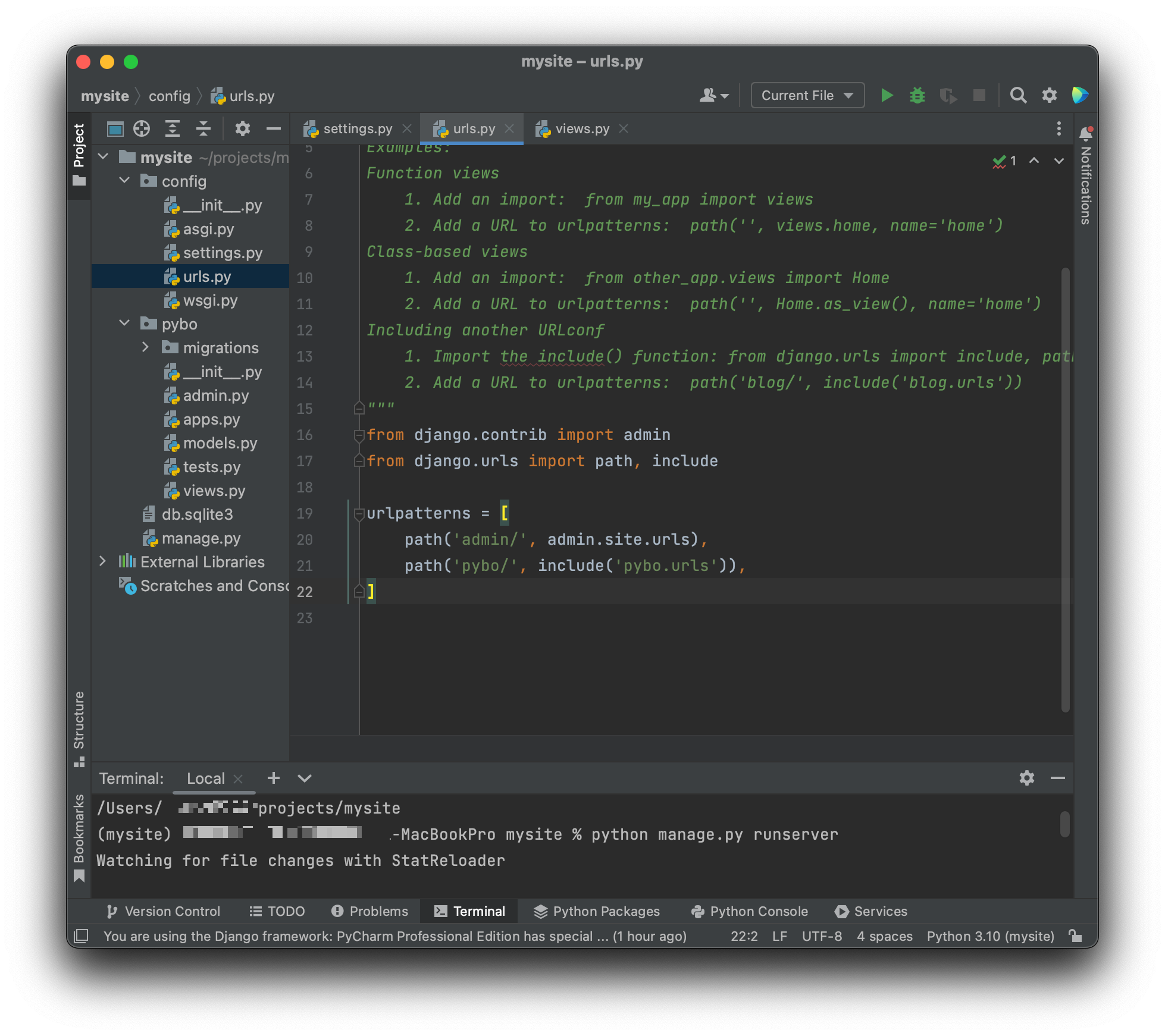
장고는 오류가 발생하면 오류의 원인을 화면에 자세히 보여주어서 오류를 파악하기가 쉽다. 오류를 해석하면 요청한 URL은 http://localhost:8000/pybo 이다. 오류 해결방법은 config.urls 파일안에 URLconf를 정의하라고 나온다. 그렇다면 그대로 해주면 된다. urls.py 파일은 페이지 요청이 발생하면 가장 먼저 호출되는 파일이다.
config.urls 파일은 projects/mysite/config/urls.py 에 있다.
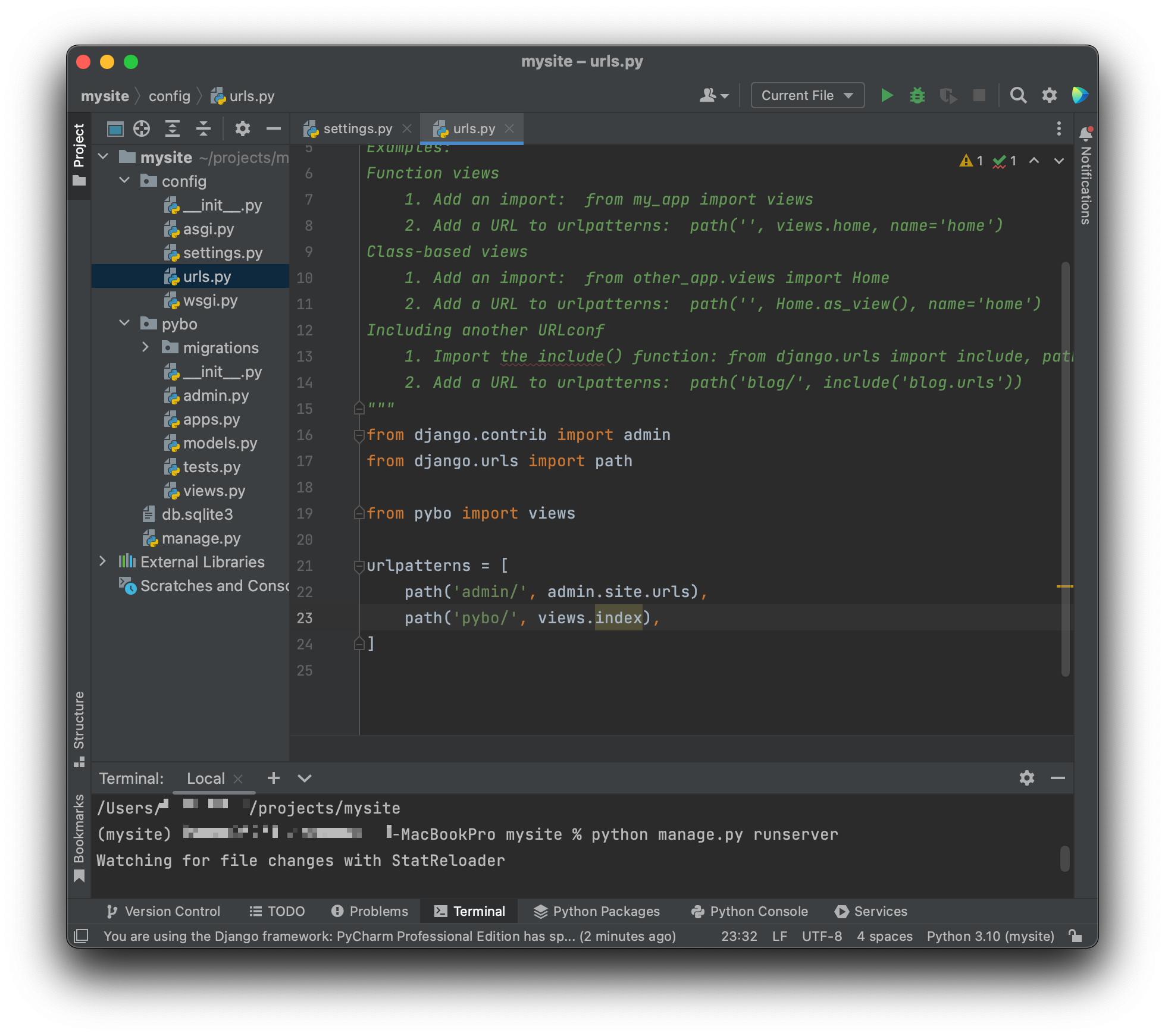
urls.py 파일을 찾아 수정해준다
19줄에 from pybo import views , 23줄에 path('pybo/', views.index), 를 추가해준 모습이다. 의미는 'pybo/' 라는 URL이 요청되면 views.index 를 호출하라는 매핑을 urlpatterns 에 추가한것이다. views.index 는 views.py 파일의 index 함수이다. pybo/ 에 / 를 추가하는 이유는 URL 을 정규화하는 장고의 기능 때문이다.
아직 views.index 를 설정하지 않았기 때문에 이 상황에서 다시 페이지를 요청하면 페이지 연결 실패가 나올것이다.
를 작성해 넣어보자 HttpResponse는 요청에 대한 응답을 할때 사용한다. index 함수의 매개변수 request 는 HTTP요청 객체이다.
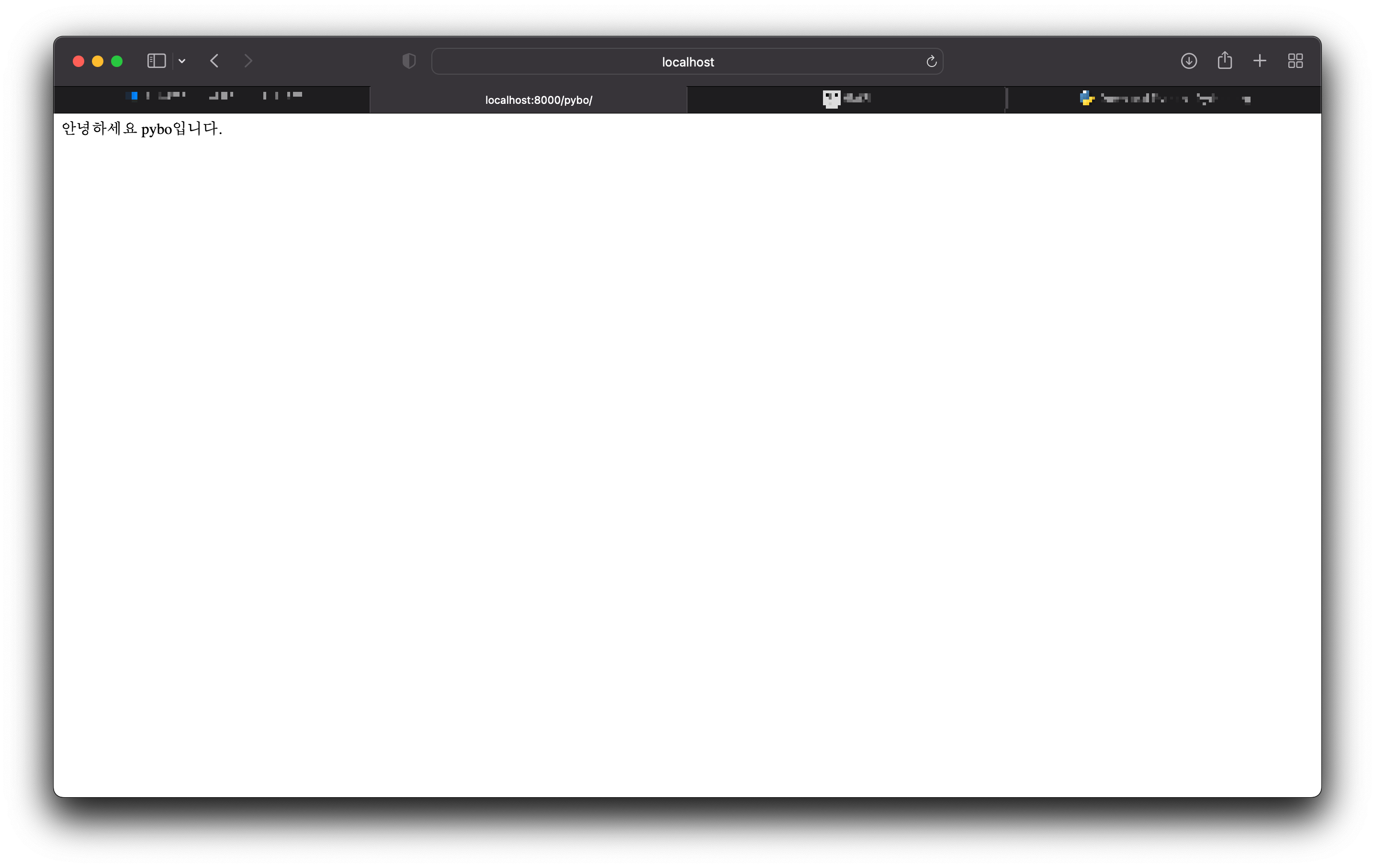
작성을 했으면 다시 페이지를 요청해보자.
설정한 문자열이 정상적으로 출력된 모습이다
지금까지 한 이 과정들은 앞으로 장고를 개발할때 반복하는 계속 반복하는 과정이다.
[URL 분리방법]
urls.py 파일을 수정해서 앞으로 pybo/page1/create 등 이런형식의 URL을 추가해야할때 config/urls.py 를 수정할 필요없이 pybo/urls.py 만 수정해 작동할수있게 해보자.
config/urls.py 를 수정한것이다
전에 적었던 urls.py 와 달라진것이 보일것이다. path('pybo/', include('pybo.urls')) 의 의미는 pybo/ 로 시작하는 페이지를 요청하면 알아서 pybo/urls.py의 파일의 매핑정보를 읽어서 처리하라는 뜻이다. pybo/urls.py 파일 보고 처리하라고 했으니 파일을 만들자.
Pybo폴더에 마우스 오른쪽 클릭 - New - File 을 한 후 파일명을 urls.py 로 파일을 만든다. 그리고 파일 안에는
사진과 같이 파일을 수정하자
사진과 같이 파일내용을 추가하자. path('',views.index) 을 보면 이전에 설정한 config/urls.py 과 다른 부분은 이 있다. 저번에 적었던 'pybo/' 가 생략되고 '' 가 들어간 이유는 이미 config/urls.py 파일에서 이미 pybo/ 로 시작하는 URL이 pybo/urls.py 파일과 먼저 매핑되었기 때문이다.
config/urls.py 에 입력한 pybo/ 와 이번에 적은 '' 이 합쳐져 최종 URL 이 'pybo/' 가 되는것이다. 만약 다른 URL 을 추가해 pybo/page1/ 을 만들고싶다면 config/urls.py 에 적은 pybo/ 와 pybo/urls.py 에 새로 양식에 맞게 'page1/' 을 적어 넣는다면 최종 URL 은 config/urls.py 에 적은 pybo/ 와 pybo/urls.py 에 적은 page1/ 이 합쳐져 pybo/page1/ 이 되는것이다.
3. 멀티태스킹 프로그램을 작성하는데 있어서 각 태스크를 프로세스로 만드는 것과 스레드로 만드는 방법 중 스레드로 만드는 방법이 유리한 이유로 맞는 것은?
② 프로세스들은 주소 공간이 완전히 분리되어 있어 공유 공간을 만들기 위해 운영체제의 도움을 받아야 하지만, 멀티스레드를 이용하는 경우 프로세스 내에 공유 변수 등을 통해 쉽게 통신할 수 있기 때문이다
4. 스레드에 관한 정보를 저장하는 구조체를 무성이라고 부르는가?
② TCB
5. 다음 중 다른 한가지는?
③ TLS(Thread Local Storage)
6. 다음 중 프로세스와 스레드 중 선택하여 문장을 완성하라.
운영체제의 실행 단위는 ( 스레드 ) 이며, ( 프로세스 ) 는 ( 스레드 ) 들이 공유하는 환경을 제공한다. ( 프로세스 ) 들은 각각 독립적인 메모리 공간에서 실행되므로 ( 프로세스 ) 사이에 데이터를 주고받는데 심각한 어려움이 있다. 응용프로그램을 실행시키기 위해 운영체제는 ( 프로세스 ) 를 만든다. 하나의 ( 프로세스 ) 가 실행되면 반드시 한 개의 ( 스레드 ) 가 자동으로 만들어지고 이것은 ( 스레드 ) 라고 부른다. 하나의 ( 프로세스 ) 는 여러 개의 ( 스레드 ) 를 가질 수 있다. ( 프로세스 ) 가 실행중이라는 뜻은 ( 프로세스 ) 속한 ( 스레드 ) 중 한 개의 ( 스레드 ) 가 현재 CPU에 의해 실행되고 있음을 뜻한다. 그러므로 운영체제 스케줄러에 의해 스케줄되는 단위는 ( 스레드 ) 이며, ( 프로세스 ) 에 속한 모든 ( 스레드 ) 가 종료할 때 ( 프로세스 ) 도 종료된다.
7. 다음 설명은 concurrency와 paralleism 중 어떤 것인지 선택하라.
(1) 1개의 CPU가 여러 스레드를 번갈아 실행할 때 cocurrency
(2) 2개의 CPU에서 2개의 스레드가 각각 동시에 실행될 때 paralleism
(3) CPU가 스레드의 입출력으로 인해 유휴(idle) 상태에 있지 않고 다른 스레드를 실행할 때 cocurrency
(4) 멀티 코어 CPU가 여러 스레드를 같은 시간에 동시에 실행할 때 paralleism
8. 다음 그림은 스레드 T1, T2, T3 가 실행되는 과정을 보여준다. cocurrency인가, parallelism인가?
cocurrency 이다
9. 스레드가 활동하는 코드, 데이터, 힙, 스택은 어떤 메모리 공간에 형성되는가?
④ 스레드가 속한 프로세스 주소 공간 내에
10. 스레드의 주소 공간에 대한 설명으로 틀린 것은?
④ 스레드 코드는 프로세스의 공간 밖에 별도의 공간에 적재된다
11. 스레드 로컬 스토리지(TLS)란 어떤 메모리 공간인가?
① 다른 스레드가 접근할 수 없는 스레드만의 사적인 공간이다
12. 스레드 A가 malloc(100)을 이용하여 동적 할당받은 100바이트 공간에 대해 틀리게 설명한 것은?
③ 스레드 A가 종료할 때 할당받은 100바이트 공간은 자동 반환되지 않는다
13. TCB에 저장되는 내용이 아닌 것은?
④ 스레드 크기
14. TCB에 저장되는 내용이 아닌 것은?
④ 스레드 시작 시간
15. 다음 중 스레드 스케줄링이 일어나는 시점이 아닌 것은?
③ 스레드가 시스템 호출을 하여 커널로 진입한 직후
16. 프로세스 컨텍스트 스위칭과 스레드 컨텍스트 스위칭을 비교하여 잘 설명하지 못한 것은?
④ 프로세스 컨텍스트 스위칭이 개념적으로 스레드 컨텍스트 스위칭보다 단순하다
17. 스레드 운용에 관한 설명 중 틀린 것은?
② 스레드가 종료되면 스레드가 속한 프로세스도 종료된다
18. 스레드 라이브러리에 포함된 것이 아닌 것은?
① 스레드에서 파일을 여는 함수
19. 커널 레벨 스레드의 정의는 무엇인가?
② 커널에 의해 스케줄되는 스레드
20. 사용자 레벨 스레드의 정의는 무엇인가?
④ 스레드 라이브러리에 의해 스케줄되는 스레드
21. 사용자 레벨 스레드의 장점이 아닌 것은?
③ 여러 스레드가 각 코어에서 동시에 실행될 수 있기 때문에 멀티 코어 CPU를 가진 시스템에 적합하다
22. 커널 레벨 스레드의 장점은?
③ 여러 스레드가 각 코어에서 동시에 실행될 수 있기 때문에 멀티 코어 CPU를 가진 시스템에 적합하다
23. 최근 들어 운영체제는 사용자가 만든 스레드를 커널 레벨 스레드로 구현하는 추세이다. 그 이유는 무엇인가?
① 응용프로그램에서 생성한 각 스레드를 멀티 코어 CPU에 할당하여 응용프로그램 실행에 높은 병렬성을 얻을 수 있기 때문
24. N개의 사용자 레벨 스레드를 1개의 커널 레벨 스레드로 매핑하는 N:1 매핑의 최대 단점은 응용프로그램에 속한 한개의 사용자 레벨 스레드가 입출력을 수행하여 볼륵 상태가 되면 응용프로그램 내의 다른 모든 사용자 레벨 스레드가 스케줄(실행)될 수 없다는 점이다. 이 과정을 자세히 설명하라.
사용자 레벨 스레드가 입출력을 수행하여 커널 레벨 스레드가 Blocked 상태가 되면 N:1 매핑이기 때문에 다른 사용자 레벨 스레드가 있음에도 불구하고 응용프로그램 전체가 중단된다. Blocked 상태가 되면 CPU 코어가 다른 커널 레벨 스레드를 할당해 다른 작업을하다 Blocked 상태가 Ready 상태로 바뀌어 커널 스케줄러에 의해 스케줄될 때 까지 기다려야한다.
25. 사용자 레벨 스레드와 커널 레벨 스레드의 매핑 기법으로 최근에 가장 많이 사용하는 것은?
② 1:1
26. 사용자 레벨 스레드와 커널 레벨 스레드의 매핑 기법으로 1:1 기법을 현재 가장 많이 사용하는 이유는?
매핑 개념이 단순하여 구현하기쉽다. 높은 병렬성을 제공하기 때문에 멀티프로세서를 가진 현대의 컴퓨터 시스템에 매우 적합하다. N:1 모델과 달리, 사용자 레벨 스레드 중 하나가 시스템 호출 중 블록 상태가 되어도, 응용프로그램 내 다른사용자 레벨 스레드는 여전히 스케줄링 가능하므로 응용프로그램 전체가 중단되는 일은없다. N:M 모델은 매핑과 스케줄링 과정이 복잡하여 현대의 운영체제에서는 거의 사용하지 않는다.
[복합 문제]
1. 그림 4-5의 맛보기 프로그램을 참고하여, 리눅스에서 다음 5가지 조건에 부합하느 멀티스레드 C 응용프로그램을 작성하라. 4개의 스레드를 활용하여 1에서 40000까지의 합을 구하여 출력한다.
(1) pthread 라이브러리를 이용하여 작성하라.
(2) 응용프로그램에 0으로 초기화된 전역 변수 int sum[4]를 선언하라.
(3) 스레드로 실행할 함수의 이름을 runner로 하라.
(4) main()에서 pthread_create() 함수를 활용하여 4개의 스레드를 연속적으로 생성하여 4개의 스레드를 동시에 실행시켜라.
- 스레드 1 : 1~10000 까지의 합을 구하고 sum[0]에 저장 pthread_create(... ... runner,"1"); //1에서 10000까지 합 구하기 - 스레드 2 : 10001~20000 까지의 합을 구하고 sum[1]에 저장 pthread_create(... ... runner,"10001"); //10001에서 20000까지 합 구하기 - 스레드 3 : 20001~30000 까지의 합을 구하고 sum[2]에 저장 pthread_create(... ... runner,"20001"); //20001에서 30000까지 합 구하기 - 스레드 4 : 30001~40000 까지의 합을 구하고 sum[3]에 저장 pthread_create(... ... runner,"30001"); //30001에서 40000까지 합 구하기
(5) main()은 4개의 스레드가 모두 종료하기를 기다린 후 sum[] 배열의 값을 모두 합쳐 그 결과를 화면에 출력하라. 다음은 이 프로그램의 이름이 prac4_1.c라고 할 때 컴파일 과정과 실행 결과를 보여준다.
$ gcc -o prac4_1 prac4_1.c -lpthread $ ./prac4_1 1에서 40000까지 4개의 스레드가 계산한 총 합은 800020000 $
#include <pthread.h> // pthread 라이브러리를 사용하기 위해 필요한 헤더 파일
#include <stdio.h>
#include <stdlib.h>
void* runner(void *param); // 스레드로 작동할 코드(함수)
int total = 0; // main 스레드와 runner가 공유하는 전역 변수
int sum[4] = { 0 };
int j = 0;
int main() {
pthread_t tid1; // 스레드의 id를 저장할 정수형 변수
pthread_t tid2; // 스레드의 id를 저장할 정수형 변수
pthread_t tid3; // 스레드의 id를 저장할 정수형 변수
pthread_t tid4; // 스레드의 id를 저장할 정수형 변수
pthread_attr_t attr; // 스레드 정보를 담을 구조체
pthread_attr_init(&attr); // 디폴트 값으로 attr 초기화
pthread_create(&tid1, &attr, runner, "1"); // runner 스레드 생성
pthread_create(&tid2, &attr, runner, "10001"); // runner 스레드 생성
pthread_create(&tid3, &attr, runner, "20001"); // runner 스레드 생성
pthread_create(&tid4, &attr, runner, "30001"); // runner 스레드 생성
// 스레드가 생성된 수 커널에 의해 언젠가 스케줄되어 실행
pthread_join(tid1, NULL); // tid 번호의 스레드 종료를 기다림
pthread_join(tid2, NULL); // tid 번호의 스레드 종료를 기다림
pthread_join(tid3, NULL); // tid 번호의 스레드 종료를 기다림
pthread_join(tid4, NULL); // tid 번호의 스레드 종료를 기다림
for (int i = 0; i < 4; i++) {
total += sum[i];
}
printf("1에서 40000까지 4개의 스레드가 계산한 총 합은 %d\n", total);
}
void* runner(void *param) { // param에 "값" 전달
int to = atoi(param); // to = "값"
int tmp = 0;
total = 0;
for (int i = to; i <= to + 9999; i++) { // to에서 to+9999까지 합계산
tmp += i;
}
sum[j] += tmp;
j++;
}
2. 앞의 문제 1을 수정하여 리눅스에서 5가지 조건에 부합하는 멀티스레드 C 응용프로그램을 작성하라. 4개의 스레드를 활용하여 1에서 40000까지의 합을 구하여 출력한다.
(1) pthread 라이브러리를 이용하여 작성하라
(2) 응용프로그램에 전역 변수 int sum을 선언하고 0을 초기화하라.
(3) 스레드로 실행할 함수의 이름은 runner로 하라
(4) main에서 pthread_create() 함수를 활용하여 4개의 스레드를 연속적으로 생성하여 4개의 스레드를 동시에 실행시켜라.
(5) main은 4개의 스레드가 모두 종료하기를 기다린 후 sum 값을 화면에 출력하라. 다음은 이 프로그램의 이름이 prac4_2.c라고 할 때 컴파일 과정과 여러 번의 실행결과를 보여준다. ( 실행결과가 실행할 때 마다 달라진다. )
$ gcc -o prac4_2 prac4_2.c -lpthread $ ./prac4_2 1에서 40000까지의 스레드가 합친 sum 변수의 값은 583862451 $ ./prac4_2 1에서 40000까지의 스레드가 합친 sum 변수의 값은 640209990 $ ./prac4_2 1에서 40000까지의 스레드가 합친 sum 변수의 값은 500849160 $
1에서 40000까지의 합은 문제 1의 결과에 따라 800020000인데, 앞의 결과 화면에는 80020000가 출력되지 않는다. 여러 번 실행해도 계속 다른 값이 출력된다. 그 이유는 무엇인지 나름대로 설명해보라.
#include <pthread.h> // pthread 라이브러리를 사용하기 위해 필요한 헤더 파일
#include <stdio.h>
#include <stdlib.h>
void* runner(void *param); // 스레드로 작동할 코드(함수)
int total = 0; // main 스레드와 runner가 공유하는 전역 변수
int sum = 0;
int main() {
pthread_t tid1; // 스레드의 id를 저장할 정수형 변수
pthread_t tid2; // 스레드의 id를 저장할 정수형 변수
pthread_t tid3; // 스레드의 id를 저장할 정수형 변수
pthread_t tid4; // 스레드의 id를 저장할 정수형 변수
pthread_attr_t attr; // 스레드 정보를 담을 구조체
pthread_attr_init(&attr); // 디폴트 값으로 attr 초기화
pthread_create(&tid1, &attr, runner, "1"); // runner 스레드 생성
pthread_create(&tid2, &attr, runner, "10001"); // runner 스레드 생성
pthread_create(&tid3, &attr, runner, "20001"); // runner 스레드 생성
pthread_create(&tid4, &attr, runner, "30001"); // runner 스레드 생성
// 스레드가 생성된 수 커널에 의해 언젠가 스케줄되어 실행
pthread_join(tid1, NULL); // tid 번호의 스레드 종료를 기다림
pthread_join(tid2, NULL); // tid 번호의 스레드 종료를 기다림
pthread_join(tid3, NULL); // tid 번호의 스레드 종료를 기다림
pthread_join(tid4, NULL); // tid 번호의 스레드 종료를 기다림
printf("1에서 40000까지 4개의 스레드가 계산한 총 합은 %d\n", sum);
}
void* runner(void *param) { // param에 "값" 전달
int to = atoi(param); // to = "값"
total = 0;
for (int i = to; i <= to + 9999; i++) { // to에서 to+9999까지 합계산
sum += i;
}
}
스케줄링에 의해 4개의 스레드가 실행되는 순서가 계속 달라지기 때문에 매번 값이 달라진다.