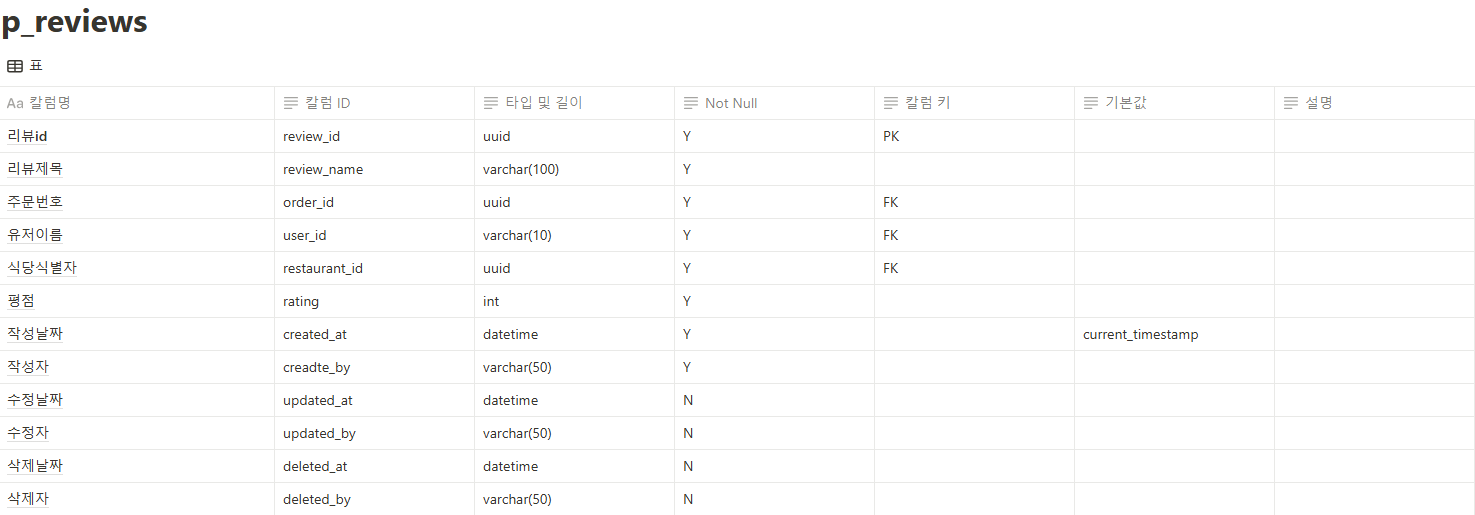
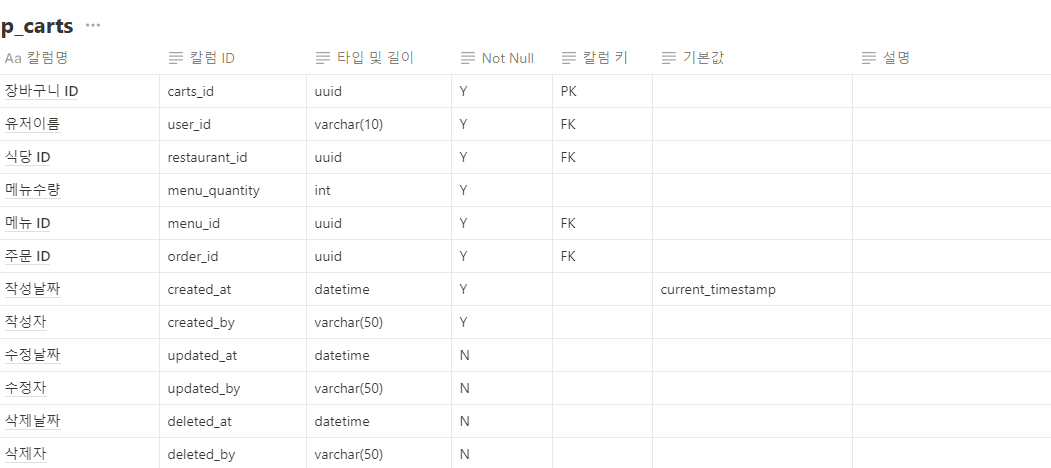
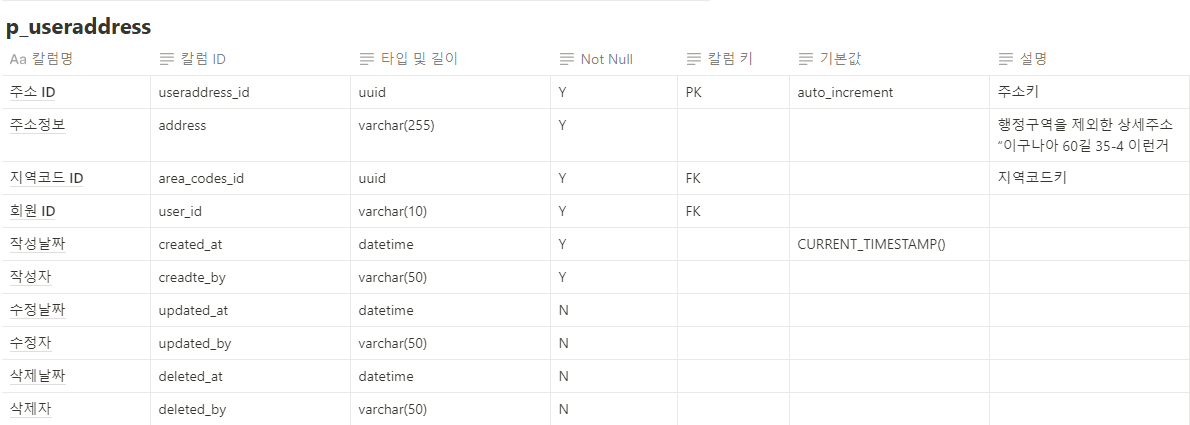
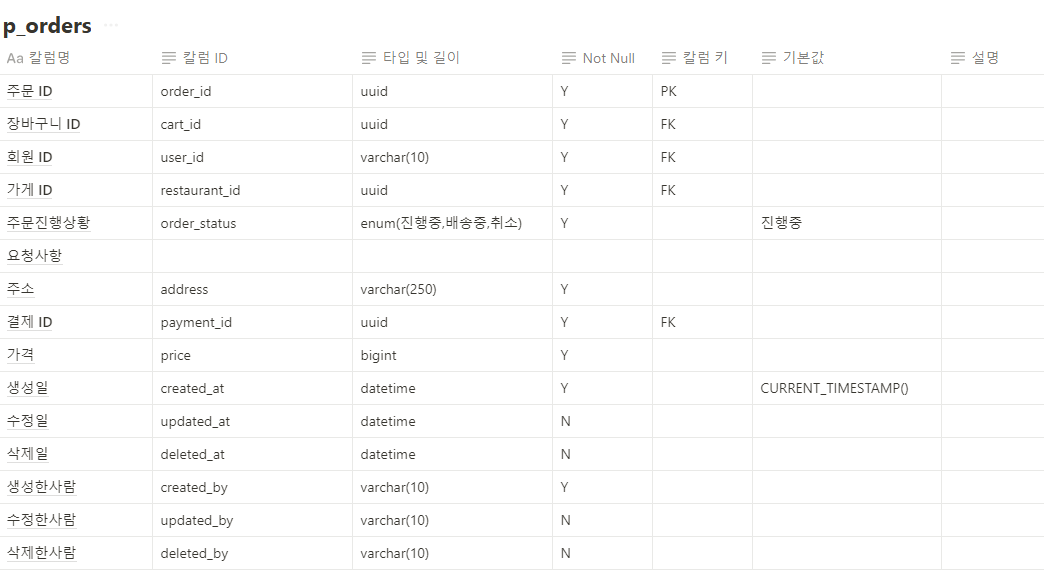
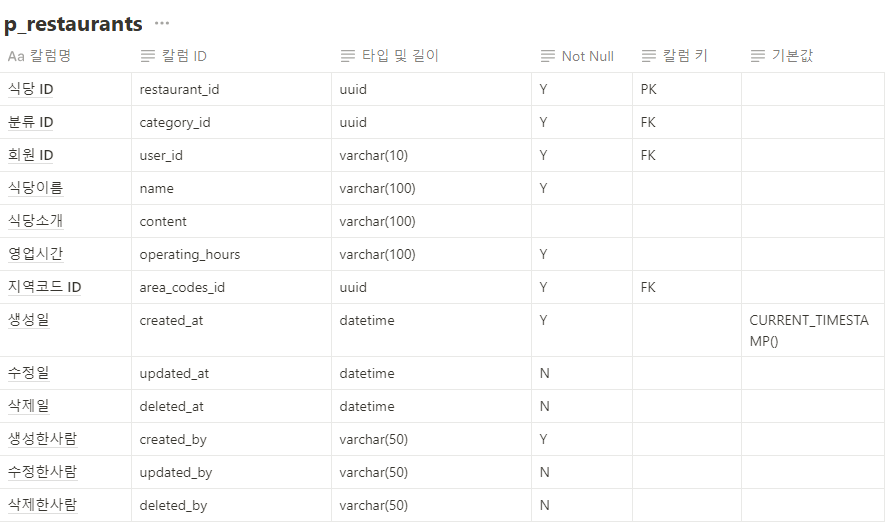
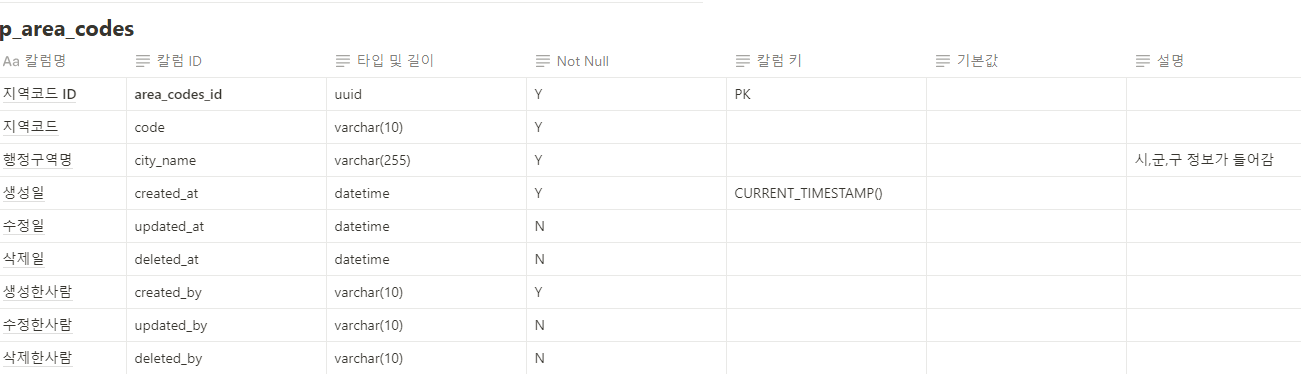
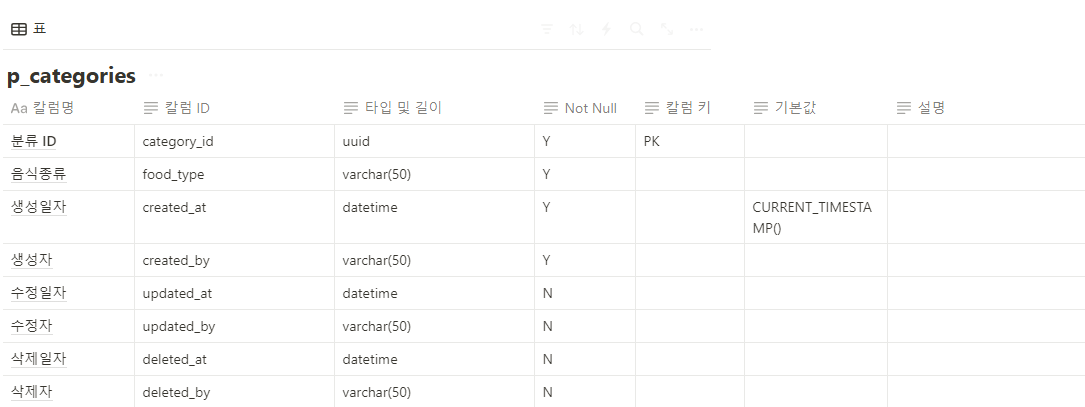
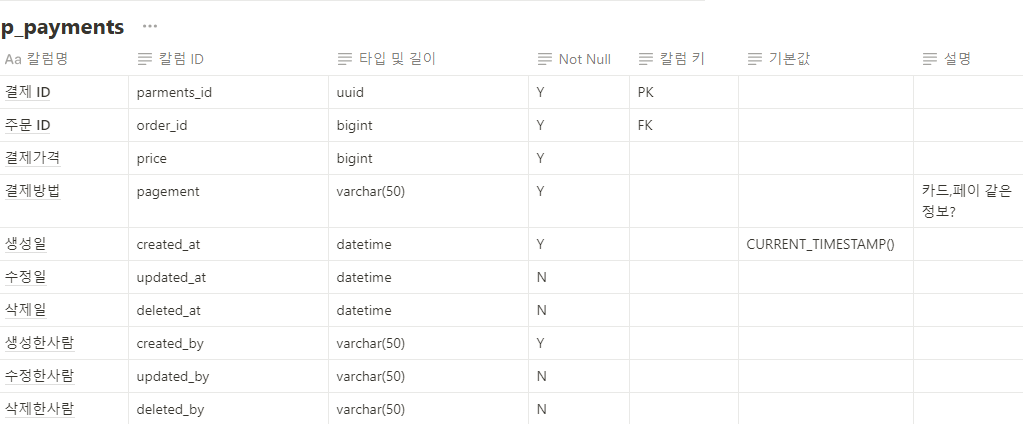
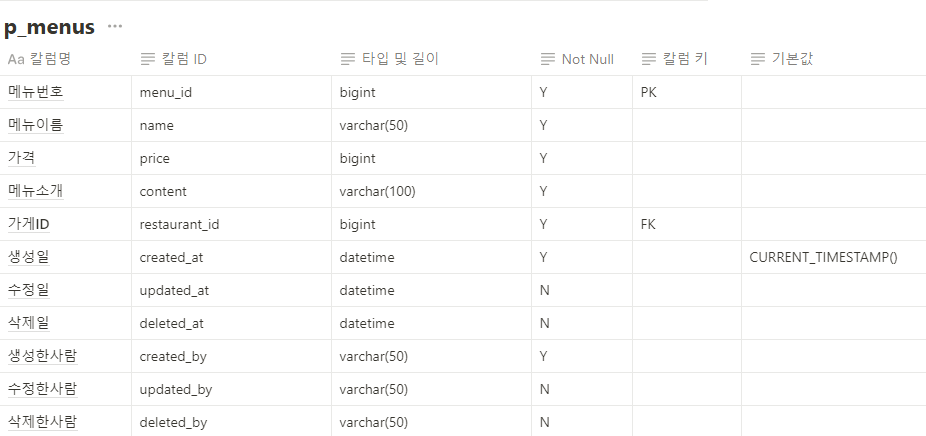
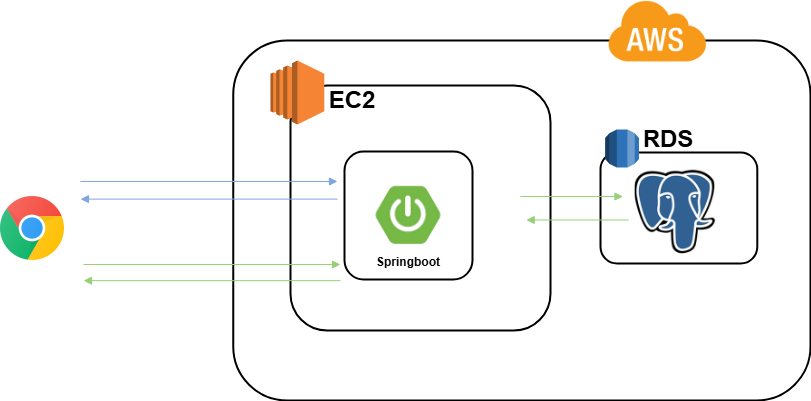
@AuthenticationPrincipal 어노테이션은 Spring Security에서 인증된 사용자 정보를 손쉽게 접근할 수 있도록 도와주는 기능입니다. Spring Security를 사용하여 인증 및 인가를 처리할 때, 인증된 사용자의 정보를 서비스 계층이나 컨트롤러에서 쉽게 가져오고자 할 때 유용합니다. 이 어노테이션은 보통 Principal 객체를 주입하는 방식과 유사하지만, 더 직관적이고 간편하게 사용할 수 있도록 도와줍니다.
1. @AuthenticationPrincipal이란?
@AuthenticationPrincipal은 Spring Security의 Authentication 객체에서 현재 인증된 사용자의 정보를 직접 가져올 수 있게 해주는 어노테이션입니다. Authentication 객체는 사용자가 로그인 시 저장된 인증 정보를 담고 있으며, 이를 통해 로그인한 사용자의 이름, 권한, 역할 등을 가져올 수 있습니다.
2. 사용 예시
2.1. 기본적인 사용
@AuthenticationPrincipal을 사용하면 인증된 사용자 객체를 쉽게 주입받을 수 있습니다. 보통 사용자 정보를 담고 있는 클래스는 UserDetails 인터페이스를 구현합니다. 예를 들어, 사용자 정보를 CustomUserDetails 클래스에 담고 있다면 다음과 같이 사용할 수 있습니다.
@Controller
public class MyController {
@GetMapping("/profile")
public String getUserProfile(@AuthenticationPrincipal CustomUserDetails userDetails) {
// 인증된 사용자 정보 사용
System.out.println("Authenticated user: " + userDetails.getUsername());
return "profile";
}
}
2.2. UserDetailsService와 함께 사용
@AuthenticationPrincipal을 사용하려면 보통 UserDetailsService를 사용하여 사용자 정보를 로드하는 방식과 함께 사용됩니다. CustomUserDetailsService 클래스를 구현하여 사용자 정보를 로드하고, Spring Security에서 제공하는 AuthenticationManager를 통해 인증을 처리하는 방식입니다.
@Service
public class CustomUserDetailsService implements UserDetailsService {
@Autowired
private UserRepository userRepository;
@Override
public UserDetails loadUserByUsername(String username) throws UsernameNotFoundException {
User user = userRepository.findByUsername(username)
.orElseThrow(() -> new UsernameNotFoundException("User not found"));
return new CustomUserDetails(user);
}
}
3. 장점
- 간결성: @AuthenticationPrincipal을 사용하면 Authentication 객체를 직접 다룰 필요 없이, 인증된 사용자 정보를 쉽게 주입받을 수 있습니다.
- 유연성: UserDetails를 구현한 클래스에 따라 사용자 정보를 다르게 설정하고 사용할 수 있습니다.
- 보안 강화: 인증된 사용자 정보만을 주입받기 때문에 보안 측면에서도 유리합니다.
4. 주의할 점
- @AuthenticationPrincipal은 주로 Principal 객체가 아닌 인증된 사용자의 상세 정보를 담고 있는 객체를 주입받기 위해 사용됩니다. 따라서 CustomUserDetails와 같은 클래스를 UserDetails 인터페이스로 구현해 사용해야 합니다.
- 인증되지 않은 사용자가 접근할 수 있는 경로에서는 @AuthenticationPrincipal을 사용할 수 없으므로, 적절한 예외 처리가 필요합니다.
5. 결론
Spring Security에서 @AuthenticationPrincipal 어노테이션은 인증된 사용자 정보를 쉽게 가져올 수 있는 매우 유용한 도구입니다. 이를 사용하면 코드가 간결해지고, Authentication 객체를 직접 다루지 않고도 인증된 사용자의 상세 정보를 손쉽게 다룰 수 있습니다. 특히 사용자 인증 및 관리가 중요한 애플리케이션에서 이 어노테이션을 활용하면 보다 깔끔하고 안전한 코드 작성이 가능합니다.