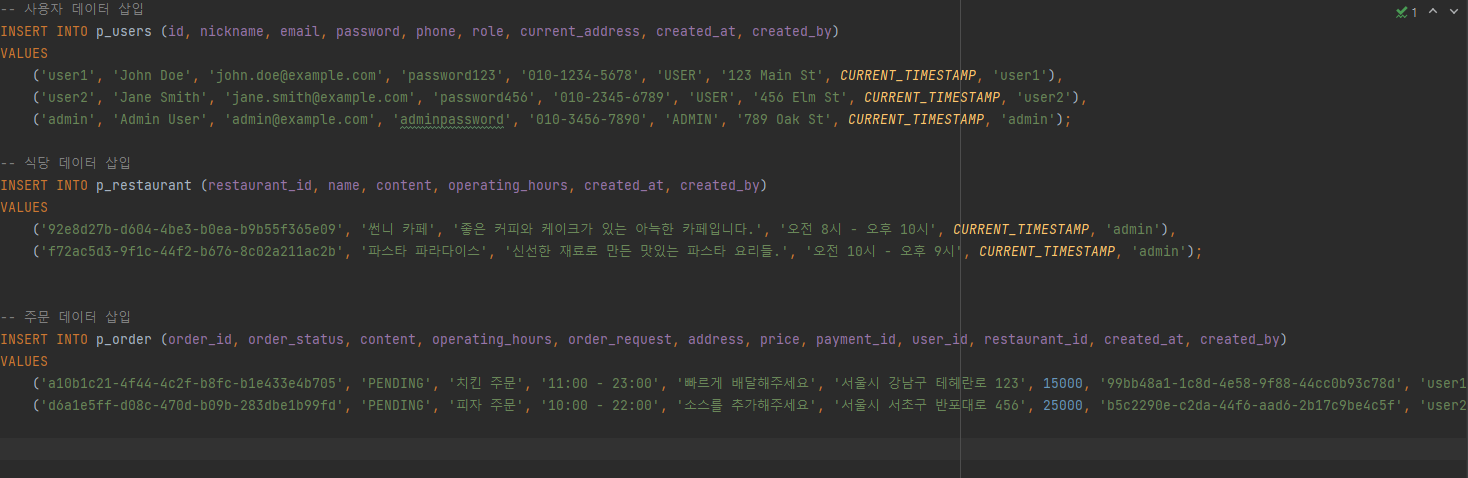
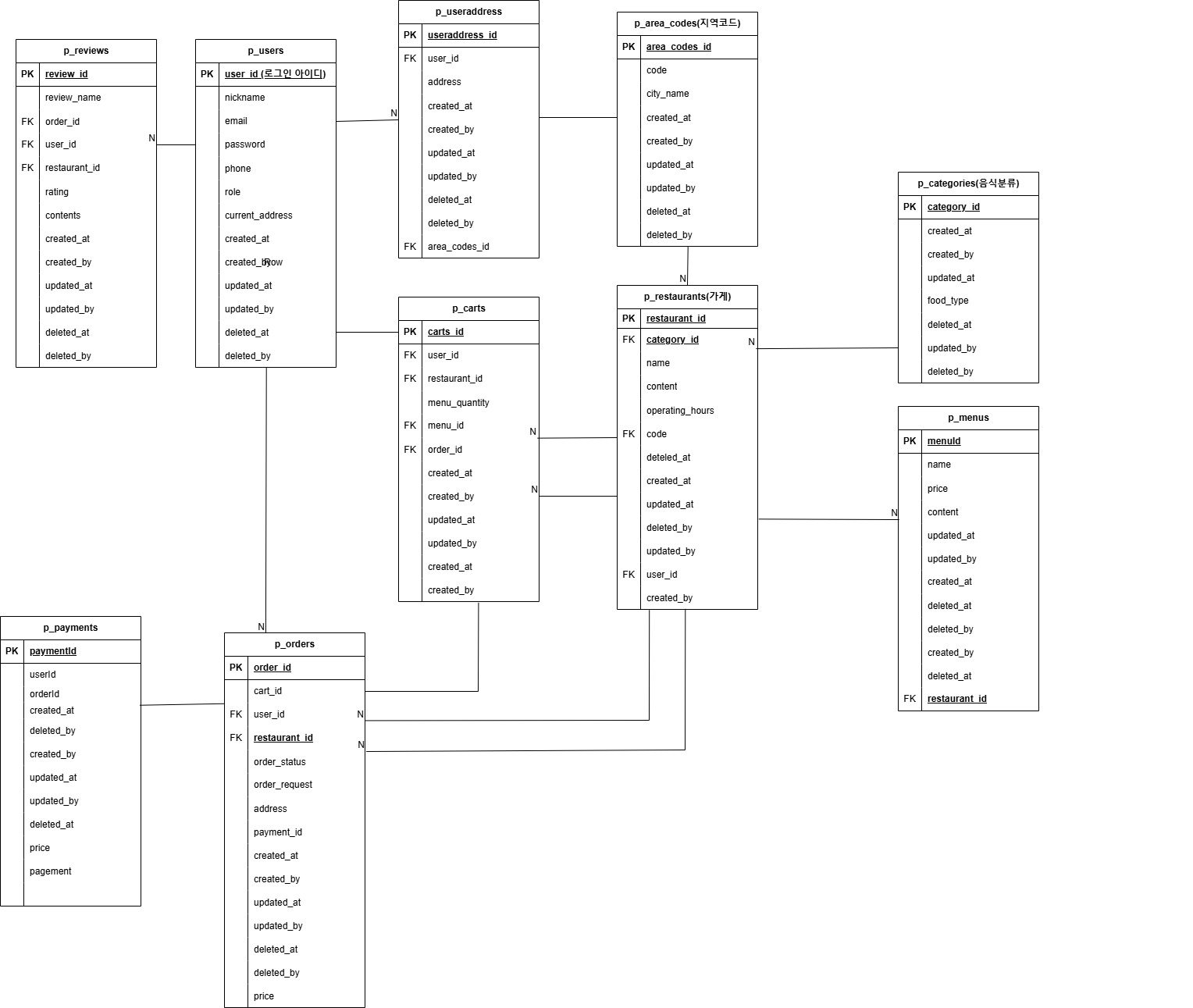
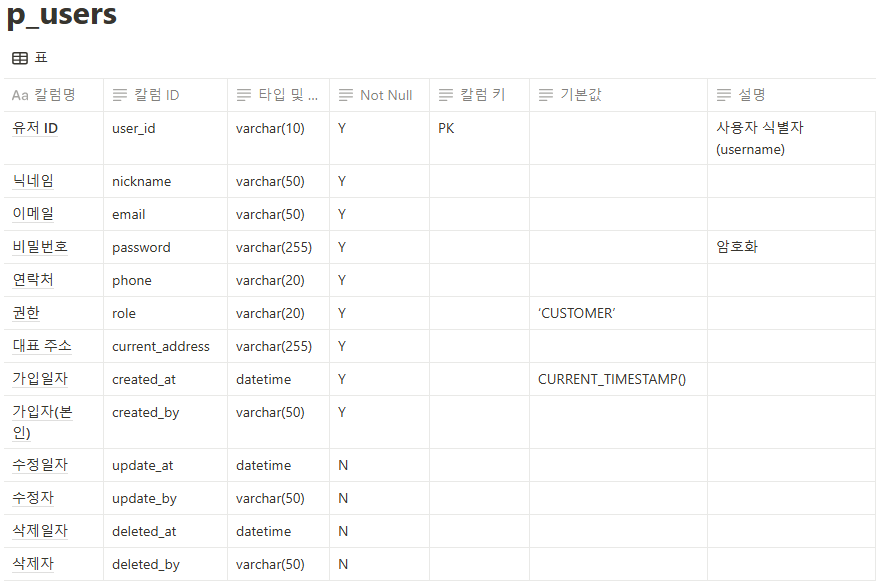
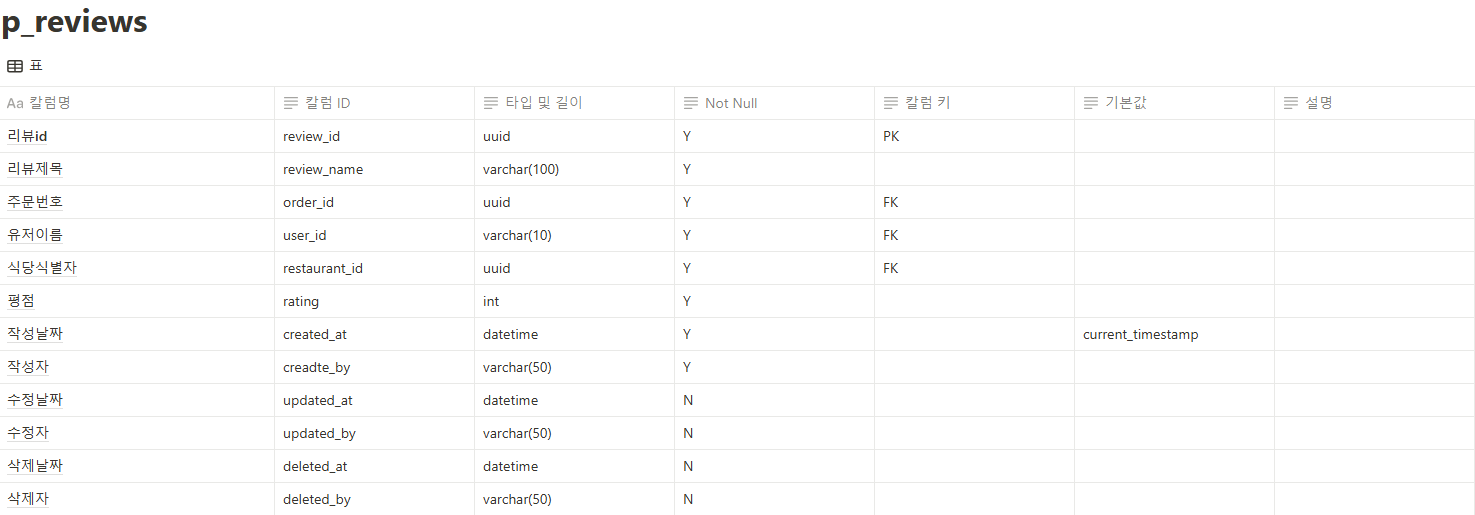
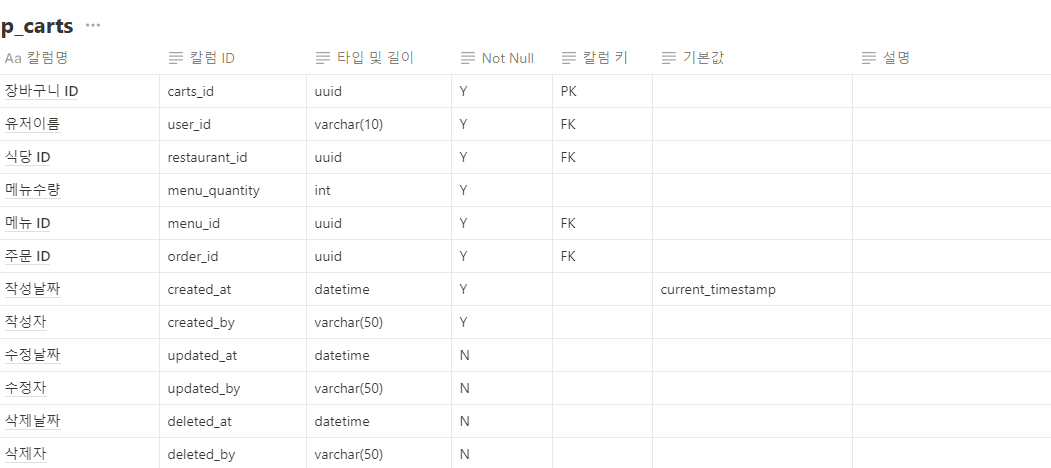
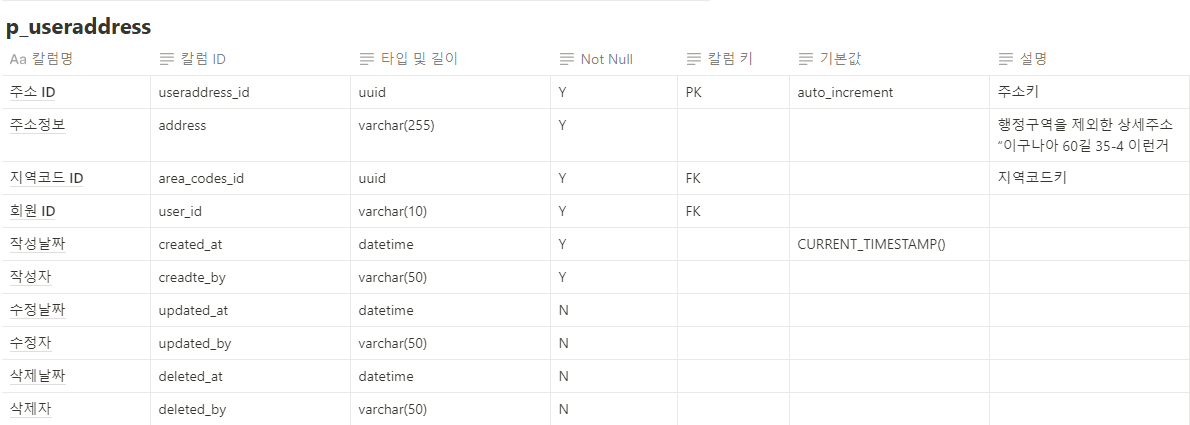
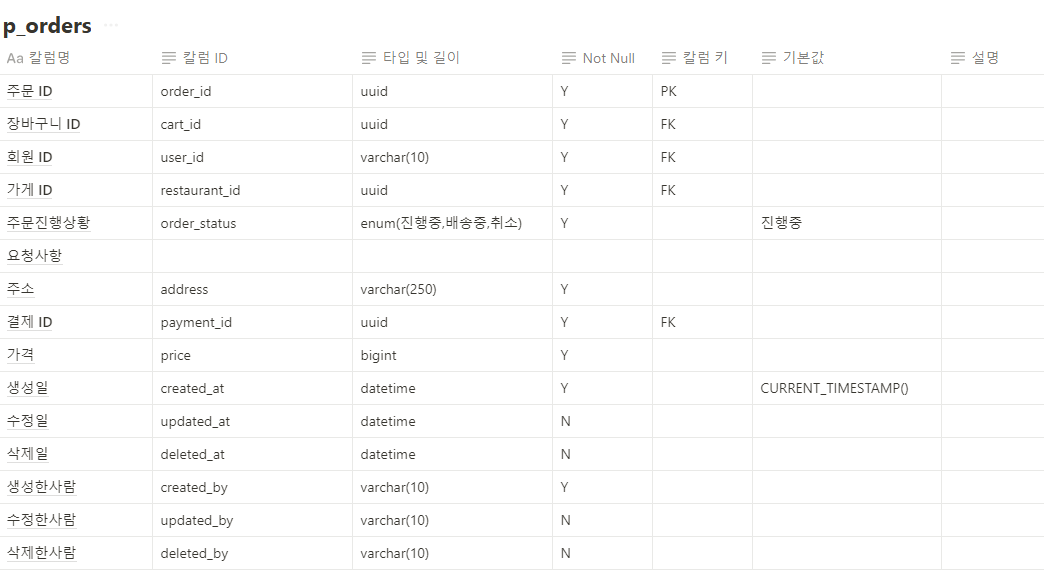
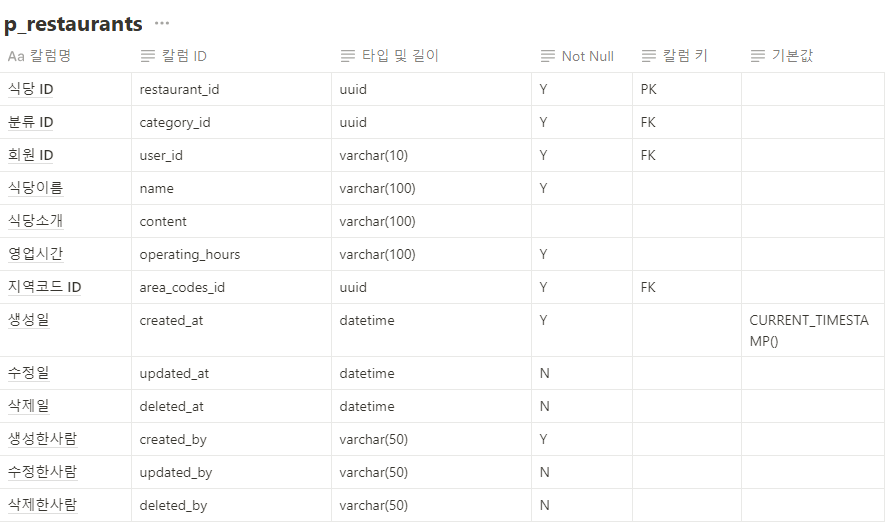
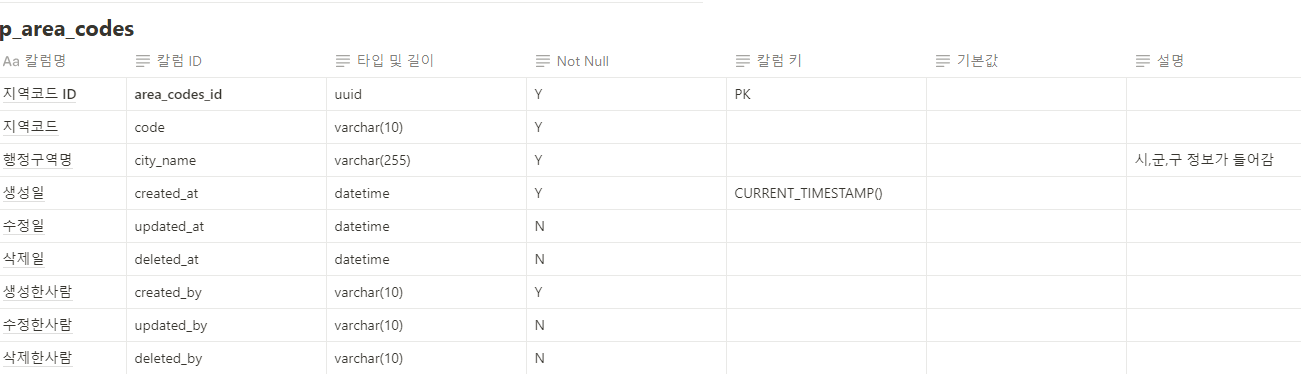
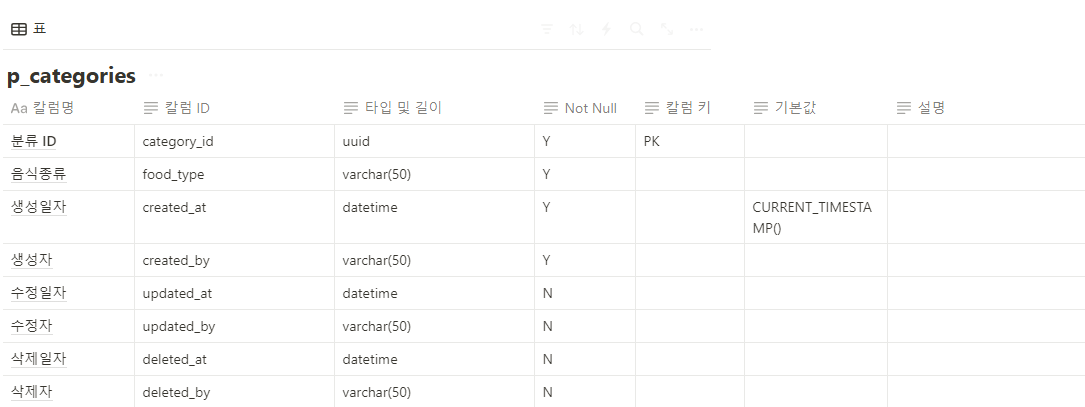
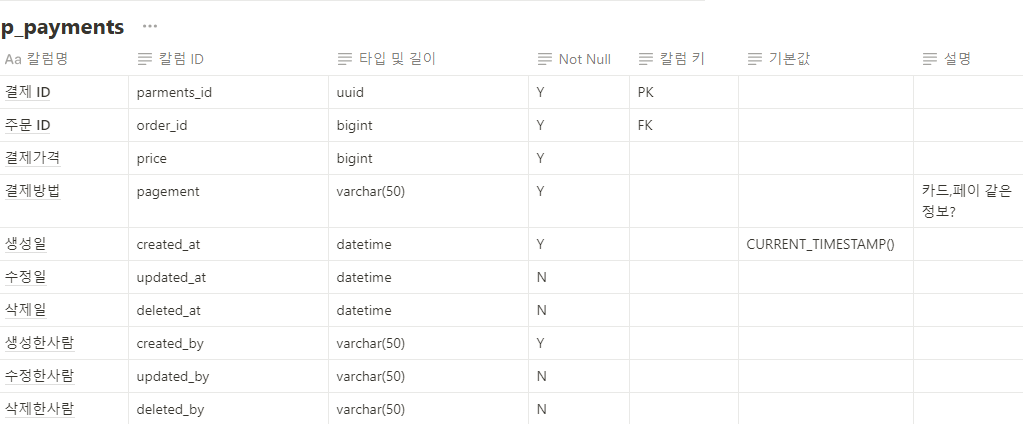
1. @Query와 leftjoin (JPQL)
엔티티들을 한번의 SQL쿼리로 조회
장점 : 간단함
단점 : JOIN FETCH 많이 사용하면 쿼리 복잡도 증가. 연관된 엔티티가 많으면 쿼리 실행 시간 증가.
2. EntityGraph
EntityGraph는 JPA에서 제공하는 기능,
특정 연관 관계를미리 로딩하도록 지정 가능
장점 : JPA표준기능이라 여러 쿼리에서 사용가능
재사용성 높음
단점 : 동적 쿼리나 매우 복잡한쿼리에는 부적함
3. @OneToMany 에서 FetchType.LAZY가 아닌 FetchType.EAGER
비추천
장점 : 간단함
단점 : 성능 저하
4. Batch Fetching
연관된 엔티티들을 한 번에 묶어서 가져오는 방식
장점 : 연관된 엔티티들을 한 번에 묶어서 조회할 수 있어 성능 최적화 가능
BatchSize를 통해 배치 크기 조절 가능
단점 : 메모리 사용량 증가
5. QueryDSL
동적 쿼리를 작성할때 JOIN을 사용해 연관된 엔티티들을 한 번에 가져오는 방식
장점 : 동적쿼리작성가능, 코드의 가독성이 높음. 실무에서 많이 사용함.
단점 : 어려움
6. 서브쿼리
장점 : 메인쿼리 단순하게 유지가능
단점 : 복잡한 sql
7. NativeQuery
SQL을 직접작성하여 원하는 데이터를 직접 가져오기.
장점 : sql을 직접작성하므로 최적화 작업을 자유롭게 가능
JPA, JPQL보다 SQL에 대한 더 높은 제어권을 가짐
단점 : JPA와 통합 어려움
DB의존적임. DB에 종속적이므로 DB를 변경할 경우 쿼리를 수정해야함
clear, flush를 자주 사용해야하고 잘 사용해야함
8. EntityGraph와 JOIN FETCH의 결합
장점 : 동적 조정가능
단점 : 복잡한 쿼리, 메모리 사용량 증가
'TIL' 카테고리의 다른 글
| Spring Security의 @AuthenticationPrincipal 이해하기 (0) | 2025.02.25 |
|---|---|
| restdocs (0) | 2025.02.20 |
| data.sql을 활용한 초기 데이터 설정 (0) | 2025.02.14 |
| Github Project & Issue (0) | 2025.02.13 |
| MSA는 필수적일까? (0) | 2025.02.11 |