QueryDSL을 활용한 동적 쿼리 최적화
1. 기술 도입 배경
기존 프로젝트에서는 JPA의 @Query 또는 Criteria API를 사용하여 복잡한 쿼리를 작성했으나,
- 가독성이 떨어지고 유지보수가 어려웠음.
- 동적 쿼리 작성 시 코드가 길어지고 복잡해짐.
- 여러 필터 조건을 유연하게 적용하기 어려웠음.
이러한 문제를 해결하기 위해 QueryDSL을 도입하여 가독성과 유지보수성을 향상하고, 동적 쿼리를 효율적으로 작성하는 방식을 적용함.
2. QueryDSL 적용 과정
- QueryDSL 환경 설정
- build.gradle에 QueryDSL 관련 의존성을 추가하고, JPAQueryFactory 빈을 설정하여 사용함.
- 동적 쿼리 구현
- 검색 필터(예: 사용자 이름, 카테고리, 작성일 등)를 조합하여 동적으로 데이터를 조회하는 기능을 구현.
- where() 절을 활용하여 조건이 있을 때만 쿼리에 추가하는 방식 적용.
- 페이징 및 성능 최적화
- 페이징을 위한 count 조회는 fetchOne()을 사용하여 불필요한 데이터 조회를 최소화함.
3. 해결한 문제 및 성과
✅ 가독성 및 유지보수성 향상
- 기존 @Query 기반의 복잡한 SQL을 QueryDSL로 변환하여 가독성을 개선.
✅ 동적 필터링 구현 - 검색 조건(이름, 날짜, 카테고리 등)을 조합하여 유연하게 검색할 수 있도록 개선.
✅ 쿼리 성능 최적화 - QueryDSL의 fetchJoin()을 활용하여 N+1 문제를 해결하고, 필요한 컬럼만 Projections.constructor()로 가져와 성능 개선.
✅ 페이징 처리
- offset()과 limit()을 활용하여 데이터 페이징 처리.
@Override
public Page<ReviewDetailResponseDto> findAllReviews(ReviewSearchCondition condition, Pageable pageable) {
int pageSize = pageable.getPageSize() > 0 ? pageable.getPageSize() : 10;
// 리뷰 목록 조회 쿼리 (fetchJoin을 통한 N+1문제 해결)
List<ReviewDetailResponseDto> content = queryFactory
.select(Projections.constructor(ReviewDetailResponseDto.class,
review.id,
order.id,
menu.id,
restaurant.id,
review.title,
review.content,
review.rating,
menu.name,
restaurant.name,
review.createdBy,
review.createdAt
))
.from(review)
.join(review.order, order).fetchJoin()
.join(order.menu, menu).fetchJoin()
.join(menu.restaurant, restaurant).fetchJoin()
.where(
review.isDeleted.isFalse(),
keywordContains(condition.keyword()),
createdAtBetween(condition.startDate(), condition.endDate())
)
.orderBy(
condition.isAsc() ? review.createdAt.asc() : review.createdAt.desc(),
condition.isAsc() ? review.updatedAt.asc() : review.updatedAt.desc()
)
.offset(pageable.getOffset())
.limit(pageSize)
.fetch();
// 총 레코드 수 조회 (fetchJoin 없이 실행하여 성능 최적화)
Long total = queryFactory
.select(review.count())
.from(review)
.join(review.order, order)
.join(order.menu, menu)
.join(menu.restaurant, restaurant)
.where(
review.isDeleted.isFalse(),
keywordContains(condition.keyword()),
createdAtBetween(condition.startDate(), condition.endDate())
)
.fetchOne();
return new PageImpl<>(content, pageable, total != null ? total : 0);
}
각각의 코드들(JPAQueryFactory, fetchjoin, projections.constructor , offset, fetchone 등 )의 사용이유들은 좀더 조사해서 추가 작성 필요.
'TIL' 카테고리의 다른 글
| RabbitMQ 기반 비동기 아키텍처 도입 성능 개선 사례 (0) | 2025.04.02 |
|---|---|
| 캐싱을 통한 성능 개선 (0) | 2025.04.01 |
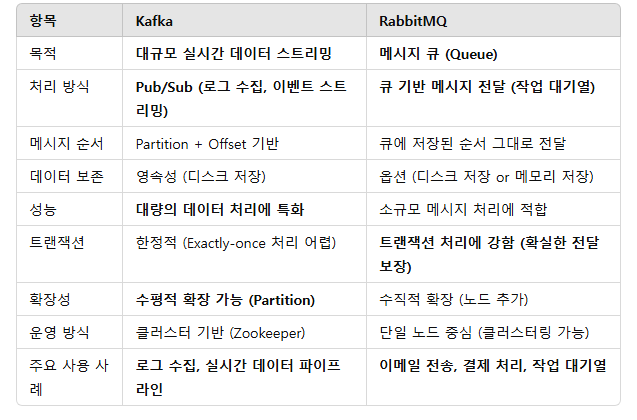
| RabbitMQ 와 Kafka (0) | 2025.03.07 |
| DB인덱싱 (0) | 2025.03.06 |
| Cache (0) | 2025.03.05 |