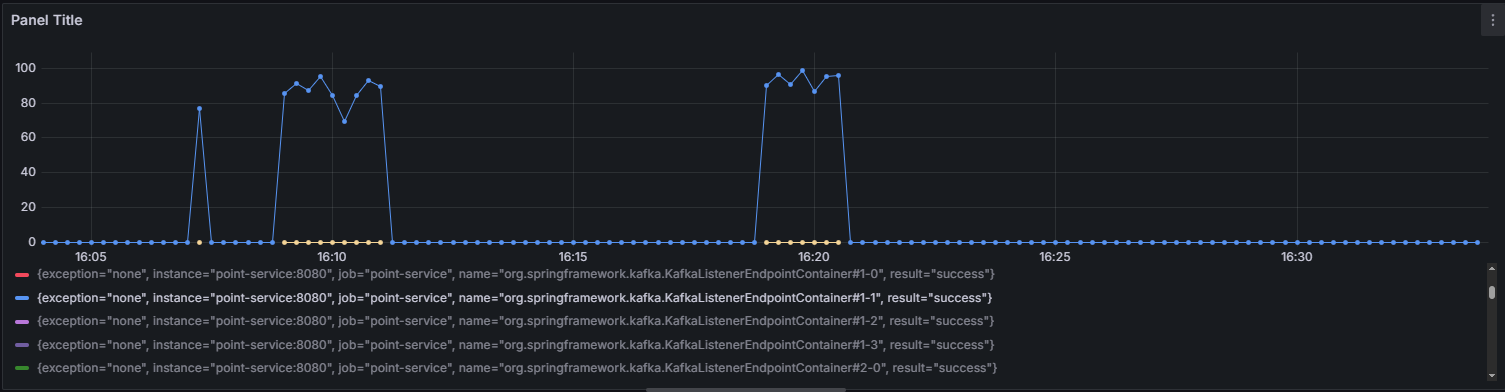
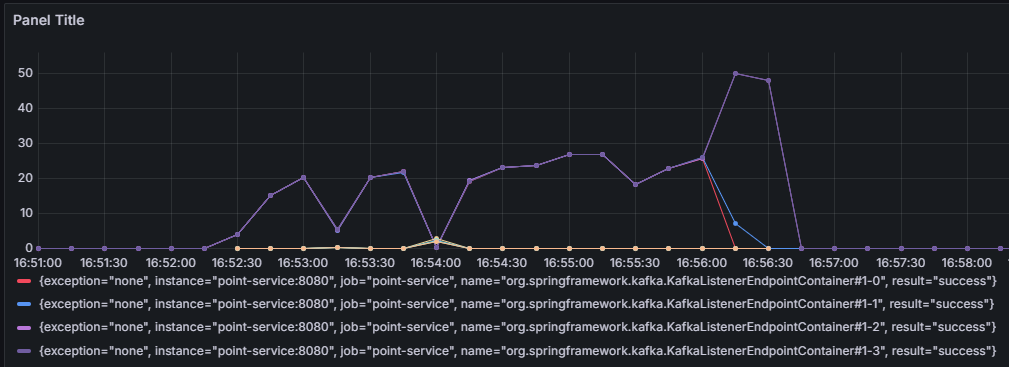
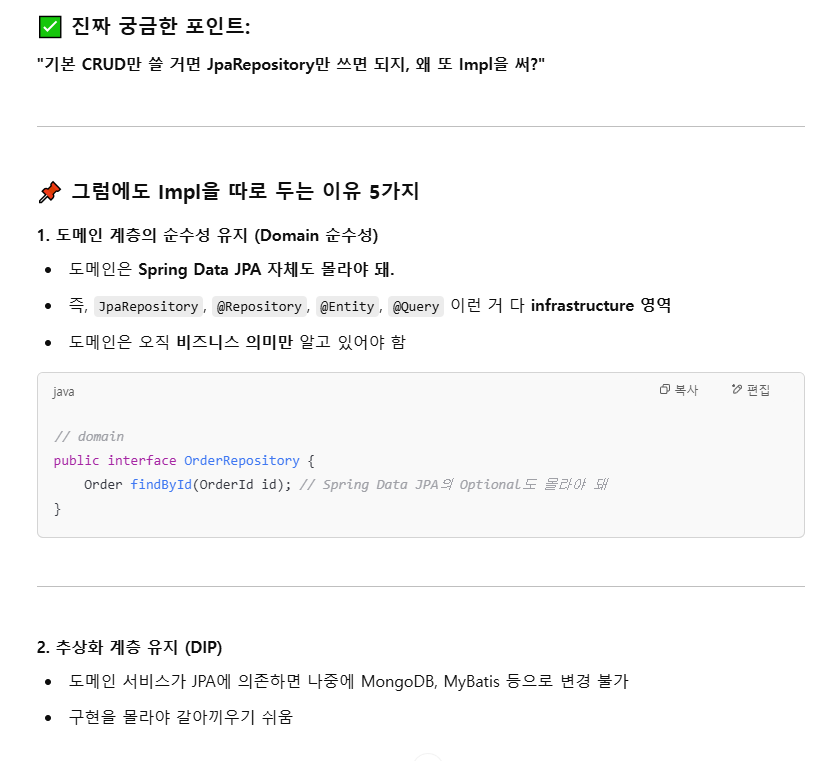
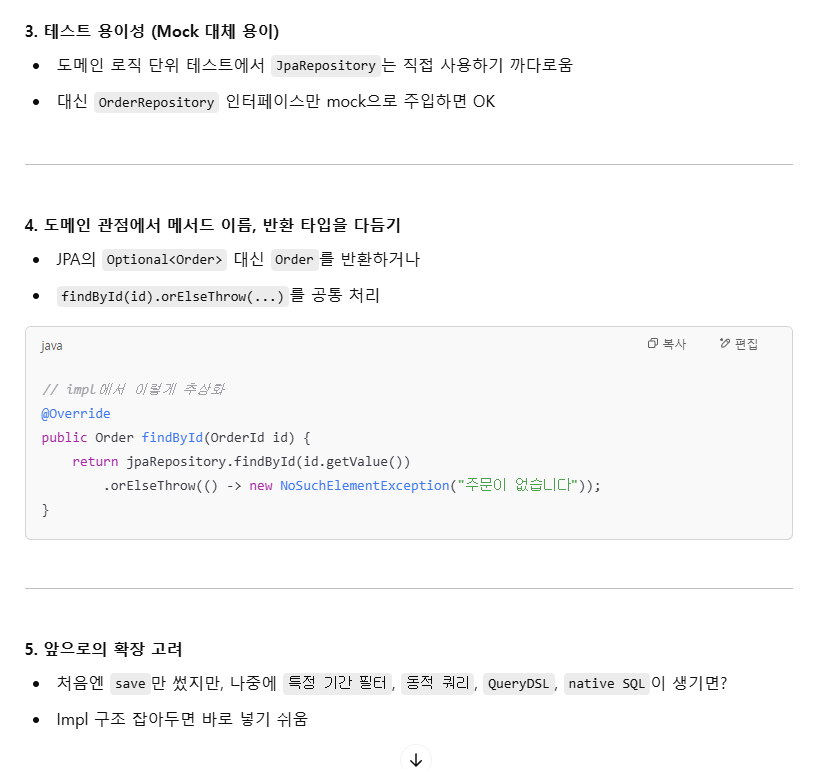
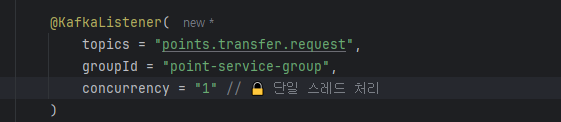
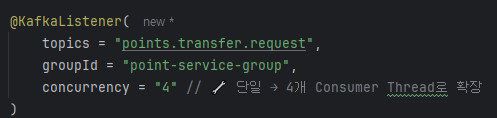
카프카 리스너에서 concurrency=4로 설정했지만 tps를 시각화한 그래프를 보면 하나의 파티션에대한 정보만 수집되고있다. 알고보니 코드는 concurrency=4를 했지만 실제 파티션은 1개라서 그렇다. 이때의 TPS는 약 85정도가 나왔다. 이를 해결하기 위해 카프카내부에 접속해 파티션을 수동으로 1개 -> 4개로 설정해주었다.
그래프에선 각각의 리스너 인스턴스(TPS)가 낮아 보여도, 이건 분산 소비의 자연스러운 현상이야. 하지만 각 리스너의 TPS를 합산해보면 : 하나의 리스너 당 약 25 TPS * 4 = 약 100TPS로 병렬성을 높여서 전체적인 TPS가 향상했다.
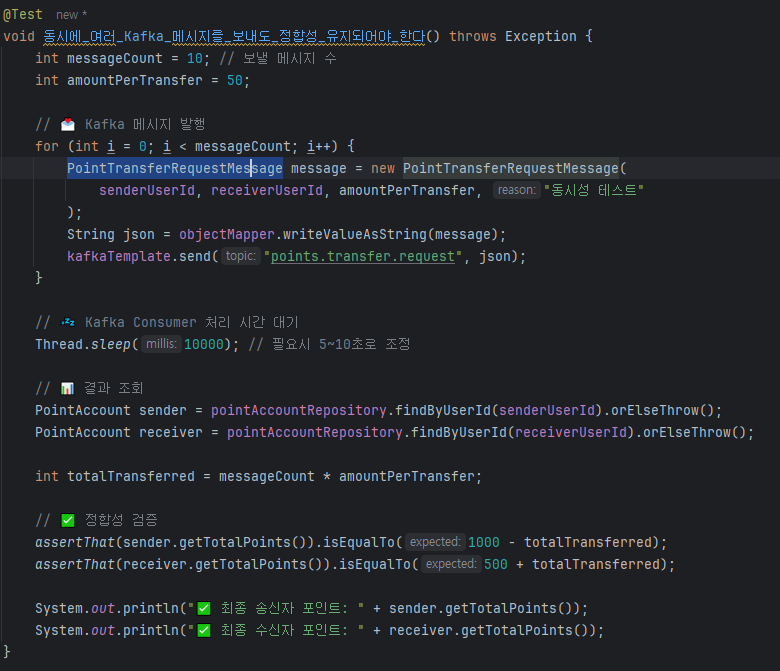
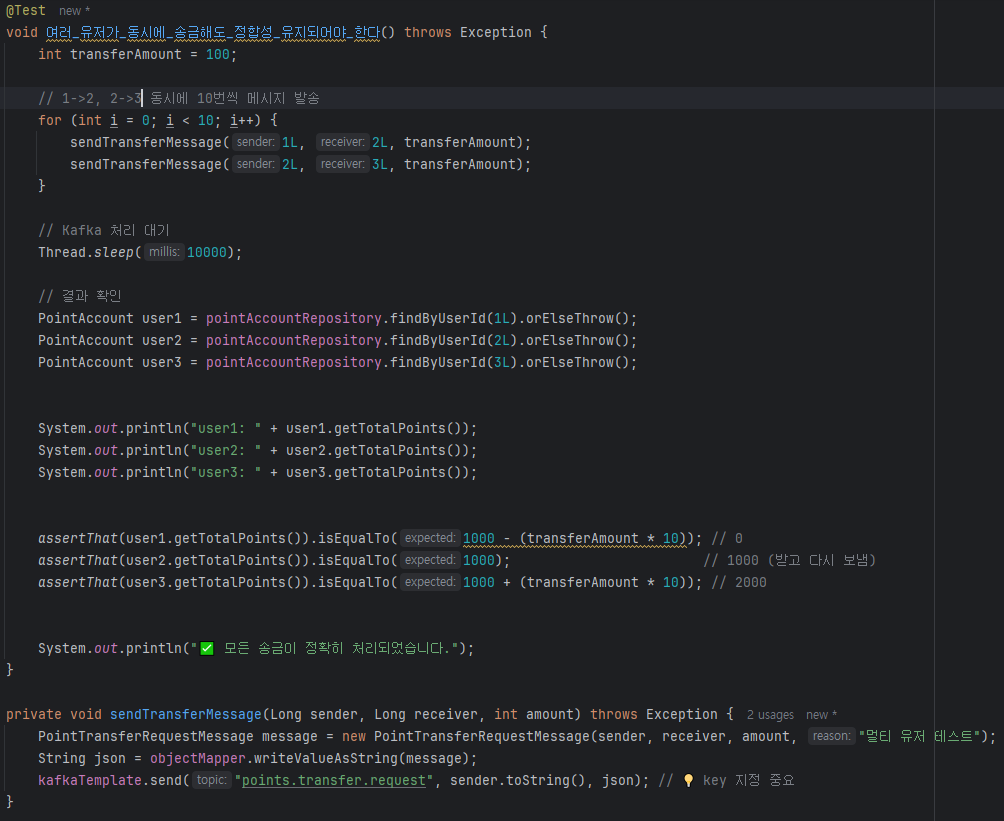
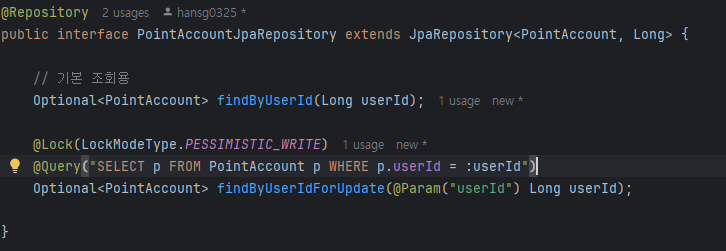
목표: 여러 사용자가 동시에 포인트를 송금할 때 데이터 정합성을 유지하는 로직을 구현하고, 데드락 발생 여부를 확인
🧪 수행한 테스트
테스트 시나리오
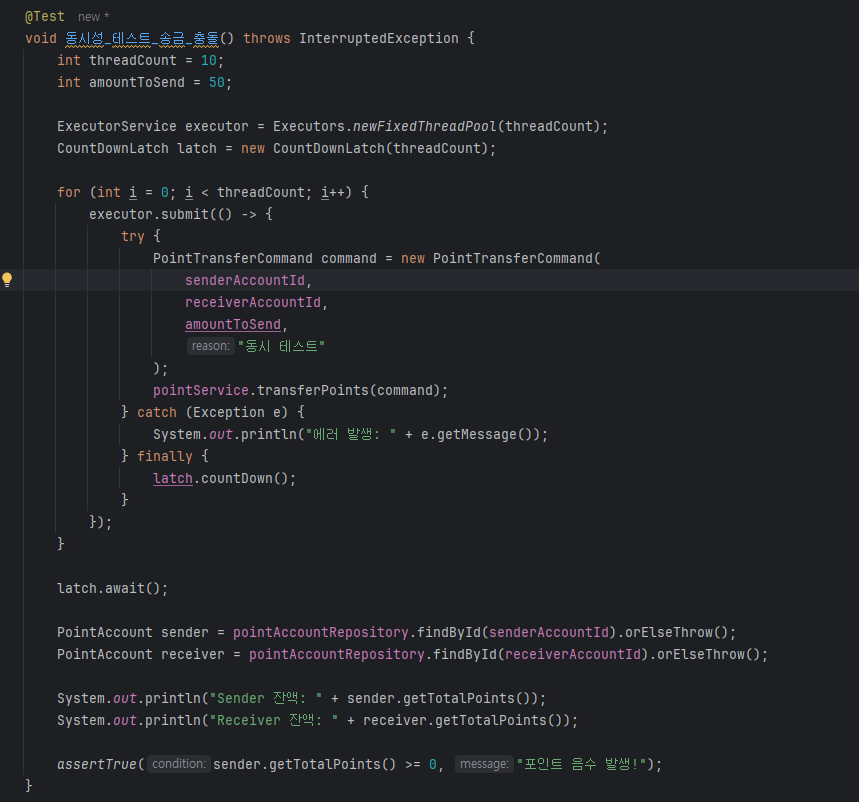
하나의 송신 계좌(sender)에서 수신 계좌(receiver)로 50 포인트씩 송금
총 10개의 쓰레드가 동시에 송금 요청을 실행
각 쓰레드는 PointService.transferPoints() 메서드를 호출
핵심 테스트 코드
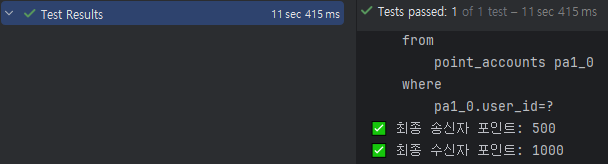
테스트 로그
2025-04-05T16:38:42.166+09:00 WARN 15836 --- [point-service] [pool-2-thread-9] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1213, SQLState: 40001
2025-04-05T16:38:42.166+09:00 WARN 15836 --- [point-service] [pool-2-thread-5] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1213, SQLState: 40001
2025-04-05T16:38:42.166+09:00 ERROR 15836 --- [point-service] [pool-2-thread-9] o.h.engine.jdbc.spi.SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction
2025-04-05T16:38:42.166+09:00 ERROR 15836 --- [point-service] [pool-2-thread-5] o.h.engine.jdbc.spi.SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction
2025-04-05T16:38:42.166+09:00 WARN 15836 --- [point-service] [pool-2-thread-3] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1213, SQLState: 40001
2025-04-05T16:38:42.167+09:00 WARN 15836 --- [point-service] [pool-2-thread-7] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1213, SQLState: 40001
2025-04-05T16:38:42.166+09:00 WARN 15836 --- [point-service] [pool-2-thread-4] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1213, SQLState: 40001
2025-04-05T16:38:42.166+09:00 WARN 15836 --- [point-service] [pool-2-thread-6] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1213, SQLState: 40001
2025-04-05T16:38:42.167+09:00 ERROR 15836 --- [point-service] [pool-2-thread-3] o.h.engine.jdbc.spi.SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction
2025-04-05T16:38:42.166+09:00 WARN 15836 --- [point-service] [ool-2-thread-10] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1213, SQLState: 40001
2025-04-05T16:38:42.167+09:00 ERROR 15836 --- [point-service] [ool-2-thread-10] o.h.engine.jdbc.spi.SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction
2025-04-05T16:38:42.166+09:00 WARN 15836 --- [point-service] [pool-2-thread-2] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1213, SQLState: 40001
2025-04-05T16:38:42.167+09:00 ERROR 15836 --- [point-service] [pool-2-thread-2] o.h.engine.jdbc.spi.SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction
2025-04-05T16:38:42.166+09:00 WARN 15836 --- [point-service] [pool-2-thread-8] o.h.engine.jdbc.spi.SqlExceptionHelper : SQL Error: 1213, SQLState: 40001
2025-04-05T16:38:42.168+09:00 ERROR 15836 --- [point-service] [pool-2-thread-8] o.h.engine.jdbc.spi.SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction
2025-04-05T16:38:42.167+09:00 ERROR 15836 --- [point-service] [pool-2-thread-7] o.h.engine.jdbc.spi.SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction
2025-04-05T16:38:42.167+09:00 ERROR 15836 --- [point-service] [pool-2-thread-4] o.h.engine.jdbc.spi.SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction
2025-04-05T16:38:42.167+09:00 ERROR 15836 --- [point-service] [pool-2-thread-6] o.h.engine.jdbc.spi.SqlExceptionHelper : Deadlock found when trying to get lock; try restarting transaction
에러 발생: could not execute statement [Deadlock found when trying to get lock; try restarting transaction] [update point_accounts set total_points=?,user_id=? where account_id=?]; SQL [update point_accounts set total_points=?,user_id=? where account_id=?]
에러 발생: could not execute statement [Deadlock found when trying to get lock; try restarting transaction] [update point_accounts set total_points=?,user_id=? where account_id=?]; SQL [update point_accounts set total_points=?,user_id=? where account_id=?]
에러 발생: could not execute statement [Deadlock found when trying to get lock; try restarting transaction] [update point_accounts set total_points=?,user_id=? where account_id=?]; SQL [update point_accounts set total_points=?,user_id=? where account_id=?]
에러 발생: could not execute statement [Deadlock found when trying to get lock; try restarting transaction] [update point_accounts set total_points=?,user_id=? where account_id=?]; SQL [update point_accounts set total_points=?,user_id=? where account_id=?]
에러 발생: could not execute statement [Deadlock found when trying to get lock; try restarting transaction] [update point_accounts set total_points=?,user_id=? where account_id=?]; SQL [update point_accounts set total_points=?,user_id=? where account_id=?]
에러 발생: could not execute statement [Deadlock found when trying to get lock; try restarting transaction] [update point_accounts set total_points=?,user_id=? where account_id=?]; SQL [update point_accounts set total_points=?,user_id=? where account_id=?]
에러 발생: could not execute statement [Deadlock found when trying to get lock; try restarting transaction] [update point_accounts set total_points=?,user_id=? where account_id=?]; SQL [update point_accounts set total_points=?,user_id=? where account_id=?]
에러 발생: could not execute statement [Deadlock found when trying to get lock; try restarting transaction] [update point_accounts set total_points=?,user_id=? where account_id=?]; SQL [update point_accounts set total_points=?,user_id=? where account_id=?]
에러 발생: could not execute statement [Deadlock found when trying to get lock; try restarting transaction] [update point_accounts set total_points=?,user_id=? where account_id=?]; SQL [update point_accounts set total_points=?,user_id=? where account_id=?]
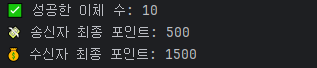
Sender 잔액: 950
Receiver 잔액: 50
Java HotSpot(TM) 64-Bit Server VM warning: Sharing is only supported for boot loader classes because bootstrap classpath has been appended
2025-04-05T16:38:42.229+09:00 INFO 15836 --- [point-service] [ionShutdownHook] j.LocalContainerEntityManagerFactoryBean : Closing JPA EntityManagerFactory for persistence unit 'default'
2025-04-05T16:38:42.232+09:00 INFO 15836 --- [point-service] [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Shutdown initiated...
2025-04-05T16:38:42.306+09:00 INFO 15836 --- [point-service] [ionShutdownHook] com.zaxxer.hikari.HikariDataSource : HikariPool-1 - Shutdown completed.
> Task :test
BUILD SUCCESSFUL in 6s
4 actionable tasks: 1 executed, 3 up-to-date
오후 4:38:42: Execution finished ':test --tests "com.timebank.pointservice.service.PointServiceTest.동시성_테스트_송금_충돌"'.
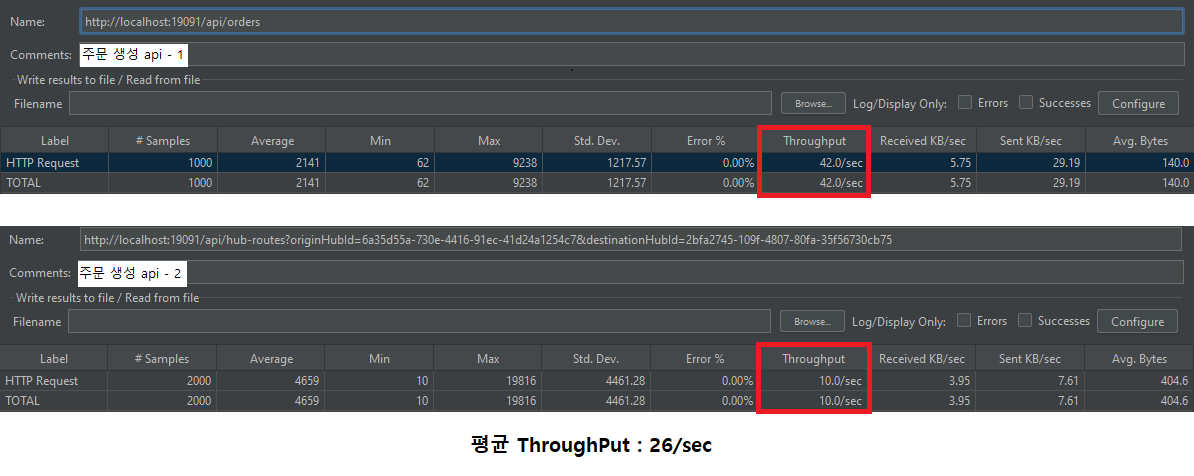
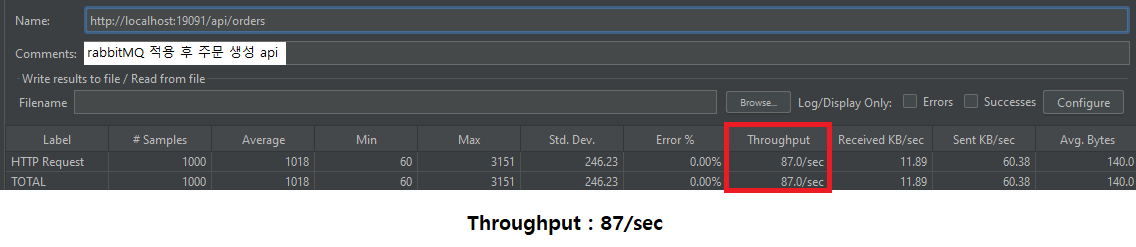
기존 시스템은 주문 생성 API를 시작으로, 배달 생성 → 배달 경로 계산 → 슬랙 메시지 전송까지 총 4단계의 API 호출이 순차적으로 진행되는 구조였다. JMeter를 활용한 성능 테스트 결과, 동기식 처리 흐름에서 평균 처리량은 약 26건/초(26 TPS) 수준으로 확인되었다.
그러나 트래픽이 증가하는 상황에서 각 API 호출이 순차적으로 진행됨에 따라 병목현상이 발생했고, 시스템 전체의 확장성에 한계가 있었다. 이에 따라 각 단계를 비동기화하여 병렬로 처리하고, **메시지 지향 미들웨어(RabbitMQ)**를 도입해 안정적이고 효율적인 비즈니스 플로우를 구성하고자 했다.
2. RabbitMQ 적용 과정
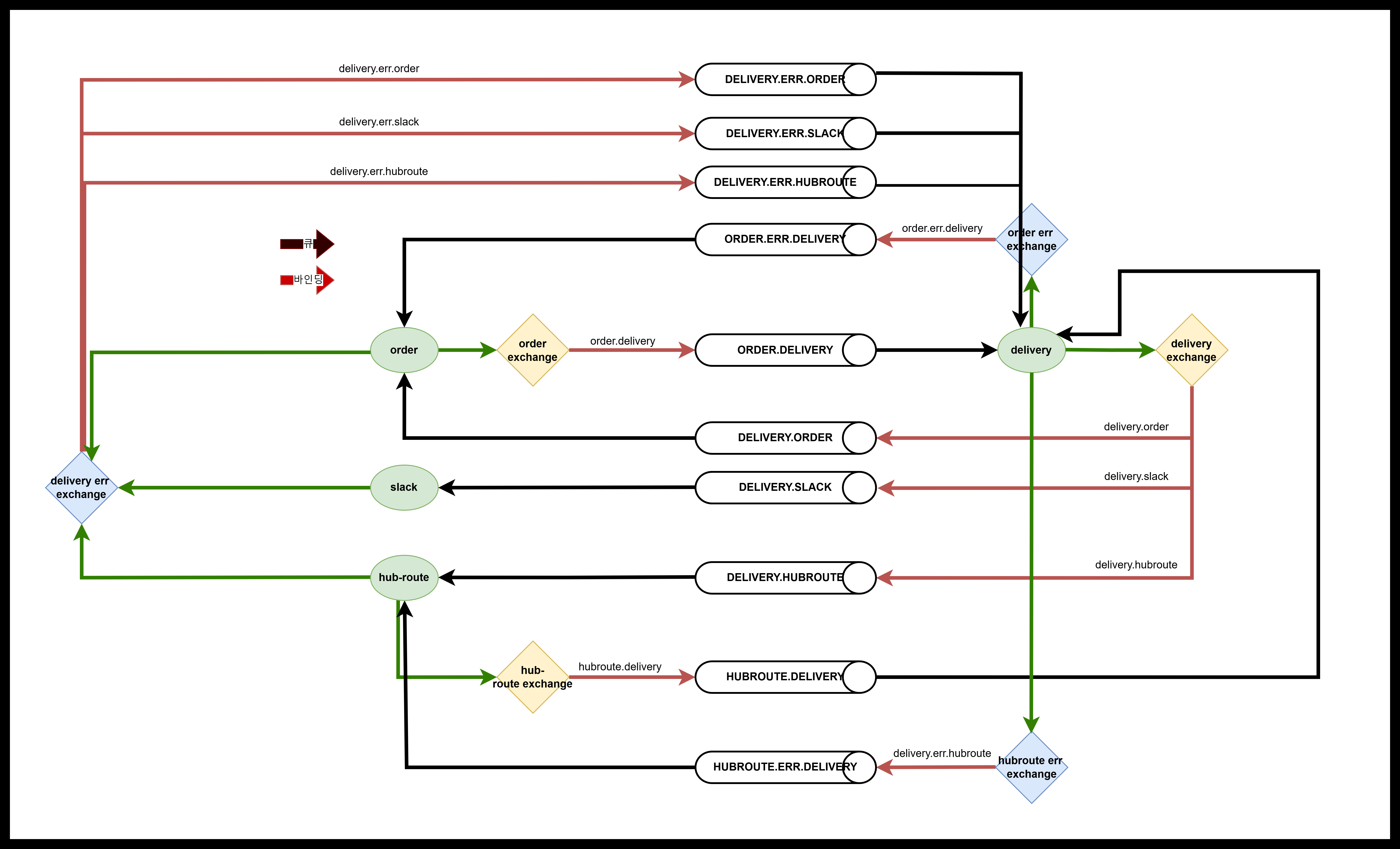
✅ 아키텍처 변경 사항
기존: 사용자 → 주문생성 API → (동기 호출) 배달생성 → 경로계산 → 슬랙알림
변경 후: 사용자 → 주문생성 API → RabbitMQ로 메시지 전송 → 컨슈머 1: 배달생성 → 메시지 발행 → 컨슈머 2: 경로계산 → 메시지 발행 → 컨슈머 3: 슬랙알림 전송
✅ 기술 적용 흐름
주문생성 API에서 메시지를 order.queue에 발행
메시지를 받은 컨슈머가 각 단계의 처리를 담당하며, 완료 시 다음 큐로 메시지 전달
전체 흐름은 메시지 기반의 엄격한 순차 실행을 유지하면서도, 비동기 처리를 통해 API 간 종속 시간을 제거
✅ 테스트 환경 구성
JMeter로 TPS 100 이상 유입 테스트 진행
처리 완료 기준은 order의 status가 배송완료로 변경되기 까지
처리 완료 로그 또는 DB 기록 기반으로 최종 처리량 산정
3. 해결한 문제 및 성과
🎯 주요 성과
항목적용 전적용 후개선폭
평균 처리량 (Throughput)
26 TPS
87 TPS
▲ 234% 증가
병목 발생률
높음 (API 순차 지연)
매우 낮음 (비동기 큐 병렬 소비)
해소
API 대기 시간
순차적 누적 발생
컨슈머 기반 비동기 처리
감소
🧠 해결한 문제
병목 현상 해소: 비동기 구조로 API 간 대기시간 제거 → 시스템 응답 시간 대폭 개선
확장성 확보: 컨슈머 수 증가를 통해 자연스러운 수평 확장이 가능해짐
유지보수 유리: 각 처리 단계가 독립적인 서비스 단위로 분리되어, 향후 개별 개선 및 로깅, 모니터링이 용이
💡 추가 성능 개선 및 RabbitMQ 사용 이유
확장성: 트래픽 증가 시 컨슈머 인스턴스 수만 늘리면 대응 가능
유연한 장애 대응: 특정 단계 장애 발생 시 해당 큐만 지연되고, 전체 서비스는 영향 없음
비동기 기반 구조 확장성: 이후에도 재고확인, 결제처리, 배송추적 등 다양한 플로우에 유연하게 연결 가능
비즈니스 로직 분리: 서비스 간 강결합을 줄이고, 각 단계를 이벤트 중심으로 전환함으로써 **도메인 중심 아키텍처(Domain-driven architecture)**로의 전환 기반 확보RabbitMQ 적용 전 평균 처리량