캐싱을 활용한 최적 경로 조회 성능 개선
1. 기술 도입 배경
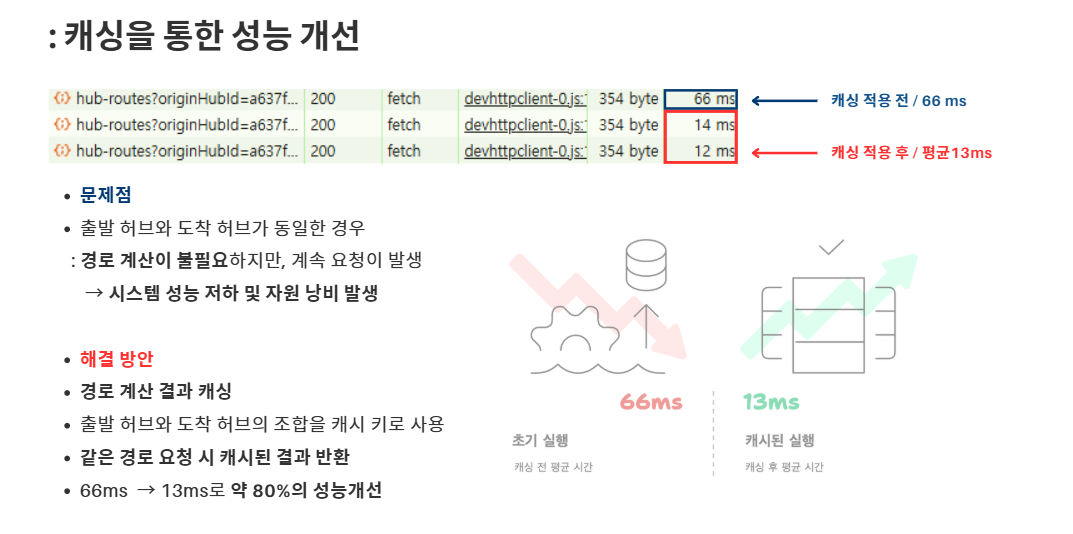
허브 간 최적 경로를 계산하는 API는 외부 API(hub-service) 호출과 복잡한 경로 계산 로직이 포함되어 있어 응답 시간이 길고 서버 부하가 컸음.
동일한 출발지와 도착지에 대해 반복 요청이 많은 상황에서, 중복 연산을 줄이기 위한 캐시 기반 성능 개선이 필요했음.
- 복잡한 계산 로직으로 인한 응답 지연
- 동일한 요청이 빈번하게 발생
- 불필요한 DB/네트워크 트래픽 증가
→ 성능 최적화를 위해 Spring Cache 기반 캐싱 도입
2. 캐싱 적용 과정
✅ Spring Cache 적용
- @Cacheable(value = "optimalRoutes", key = "#originHubId + ':' + #destinationHubId") 적용
- origin과 destination 허브 ID 조합을 캐시 key로 설정
- 동일 요청 시, 계산 없이 캐시된 결과 반환
✅ 트랜잭션과의 조합
- @Transactional과 함께 사용하여 DB 접근 일관성 유지
- 캐시는 메서드 진입 시점에 적용됨 (side effect 없음)
✅ 예외 처리 및 안전성 확보
- 허브 정보가 없을 경우 예외 처리하여 캐시 오염 방지
- 외부 API 실패 시에도 안정적으로 작동하도록 구성
3. 해결한 문제 및 성과
✅ 중복 계산 제거로 성능 향상
- 평균 응답 시간: 66ms → 13ms로 단축
- 약 80% 성능 개선
✅ 가독성 높은 캐시 로직
- 비즈니스 로직에 영향을 주지 않는 방식으로 캐시 구현
- 키 조합 방식으로 유연한 캐싱 가능
✅ 서버 부하 감소 및 안정성 향상
- 트래픽 급증 시에도 캐시 덕분에 처리량 유지
- 외부 시스템 부하 분산
✅ 향후 확장 고려
- Redis로 캐시 스토리지를 변경해 분산 환경 대응 가능
- TTL(Time To Live), 캐시 무효화 전략 도입 여지 확보
✅ 예외 처리
- Hub 정보가 존재하지 않을 경우 RuntimeException 처리
- 실패한 요청이 캐시에 저장되지 않도록 설계
4. 핵심 코드 예시
@Cacheable(value = "optimalRoutes", key = "#originHubId + ':' + #destinationHubId")
@Transactional
public List<Map<String, UUID>> findOptimalRoute(UUID originHubId, UUID destinationHubId) {
var origin = hubService.getHubById(originHubId).getBody().getData();
var destination = hubService.getHubById(destinationHubId).getBody().getData();
if (origin == null || destination == null) {
throw new RuntimeException("허브 정보를 찾을 수 없습니다.");
}
return hubRouteDomainService.findOptimalRoute(
hubRouteRepository.findAll(), originHubId, destinationHubId
);
}'TIL' 카테고리의 다른 글
| 포인트 송금 시스템에서의 동시성 처리 및 데드락 이슈 (0) | 2025.04.05 |
|---|---|
| RabbitMQ 기반 비동기 아키텍처 도입 성능 개선 사례 (0) | 2025.04.02 |
| QueryDSL을 활용한 동적 쿼리 최적화 (0) | 2025.03.31 |
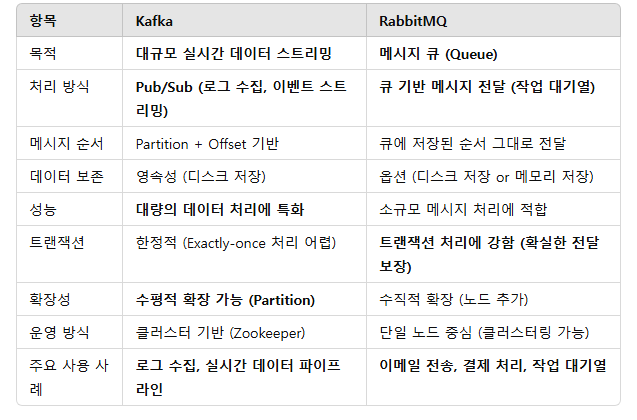
| RabbitMQ 와 Kafka (0) | 2025.03.07 |
| DB인덱싱 (0) | 2025.03.06 |